Bauplan’s MCP Server



Today we are releasing the Bauplan MCP Server in beta. An MCP server is a bridge that lets AI assistants like Claude Desktop, Claude Code, or Cursor talk directly to your tools. In this case, it gives them full access to your Bauplan lakehouse: tables, branches, pipelines, and queries, all through natural language.
Unlike other MCP servers that only expose metadata or a single interface, Bauplan’s MCP server covers the entire lakehouse lifecycle. That means an LLM can both answer questions about your data and take infrastructure actions like creating a branch, running a pipeline, or merging results back to main.
What does the Bauplan MCP Server do?
The Bauplan MCP server is now available in beta under an MIT license. It gives AI assistants like Claude Code, Claude Desktop, or Cursor direct access to your Bauplan lakehouse for development. Once connected, your assistant can use Bauplan’s MCP server for:
- Data operations: list tables, inspect schemas, query and join data, export query results.
- Lakehouse management: create Iceberg tables, plan and define schema imports, apply schema changes, and deal programmatically with conflicts.
- Git data management: create, merge, and delete data branches, travel back in time through different table versions, inspect the data lake commit history, and revert a table to previous states.
- Pipeline engine and job management: run Bauplan projects from a specified branch and directory either interactively or in detach mode. List all runtime jobs, retrieve the logs, and track status.
- User info inspection: check which Bauplan profile is being used.
Get started
Getting started takes one minute. If you have a Bauplan API key and an MCP-capable AI assistant, you can run:
Then connect it to your assistant, for example with Claude Code:
To add the Bauplan MCP server to Claude Desktop, follow the instructions on the Bauplan MCP repository to automatically generate a configuration to add to and then follow the guide to edit your configuration in your claude_desktop_config.json.
Use Cases
1. Data discovery
You can ask your assistant business questions about data in the lakehouse. For instance:
”List all the tables in the sandbox, providing their schema and give a brief description of the data in them. Make an app that I can share with my colleagues with the information you find”
The server responds with a structured inventory, including names, schemas, and descriptions. Perfect for business users exploring the lakehouse or agents building context before a query.
2. Query data
Because Bauplan has a built-in query engine it is easy to ask questions that require manipulation and join of data:
”The table taxi_fhvhv contains the NYC taxi dataset, there is also a table with geospatial information but I don't remember its name. Can you find it and then tell me what are the top NY neighborhood in terms of numbers of taxi rides in 2024?”The assistant generates and executes SQL directly against your Iceberg tables. Results can be returned inline, exported as a file or can be visualized
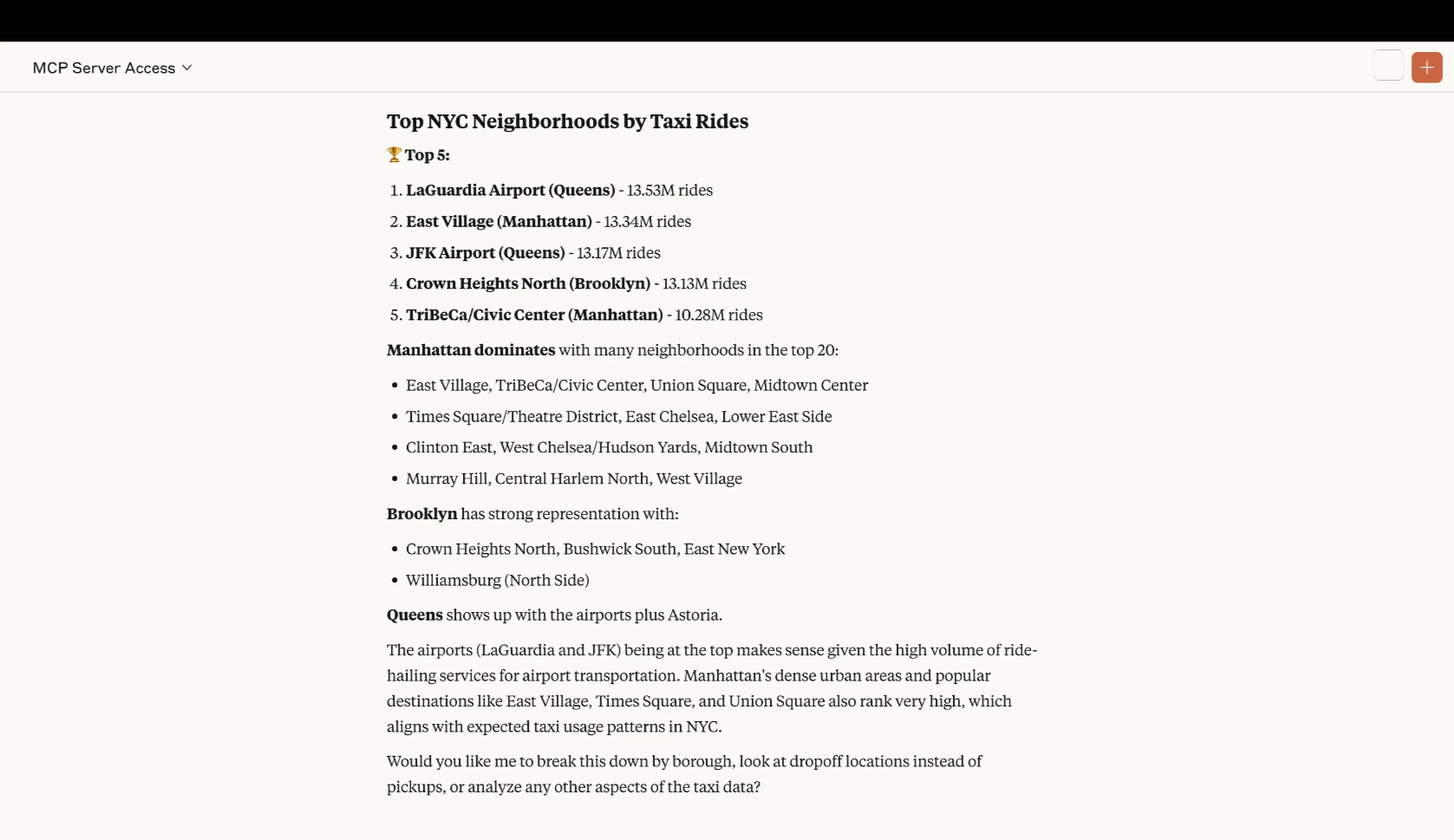
3. Lakehouse infrastructure management
One of Bauplan’s superpowers is its Git-for-data branching model, which brings version control and safe isolation to the lakehouse. Instead of writing directly into production tables, every change happens in a branch, just like with code. This makes ingestion, testing, and publishing atomic and auditable.
With MCP, that entire workflow can be orchestrated in natural language. An assistant can both manipulate the data (create tables, run queries) and control the infrastructure (branches, merges, commits) from the same interface.
For example, you could say:
“I want you to import new data using a write-audit-publish (WAP) pattern: create a new branch from main, import yesterday’s data from s3://data/to/be/imported into staging, and block the merge if nulls are detected.
"Name the tabletaxi_dataset_082025, import it in a namespace calledtaxi_dataset, return the import branch hash and its commit history, and write a sharable report when you are done.”
Behind the scenes, Bauplan + MCP translates this into a safe sequence of operations: zero-copy cloning production into an import branch, applying schema and data changes in isolation, running expectations, and finally merging atomically if tests pass. The result is a fully automated WAP ingestion pipeline, expressed in plain English, with full lineage and history captured in the data lake.
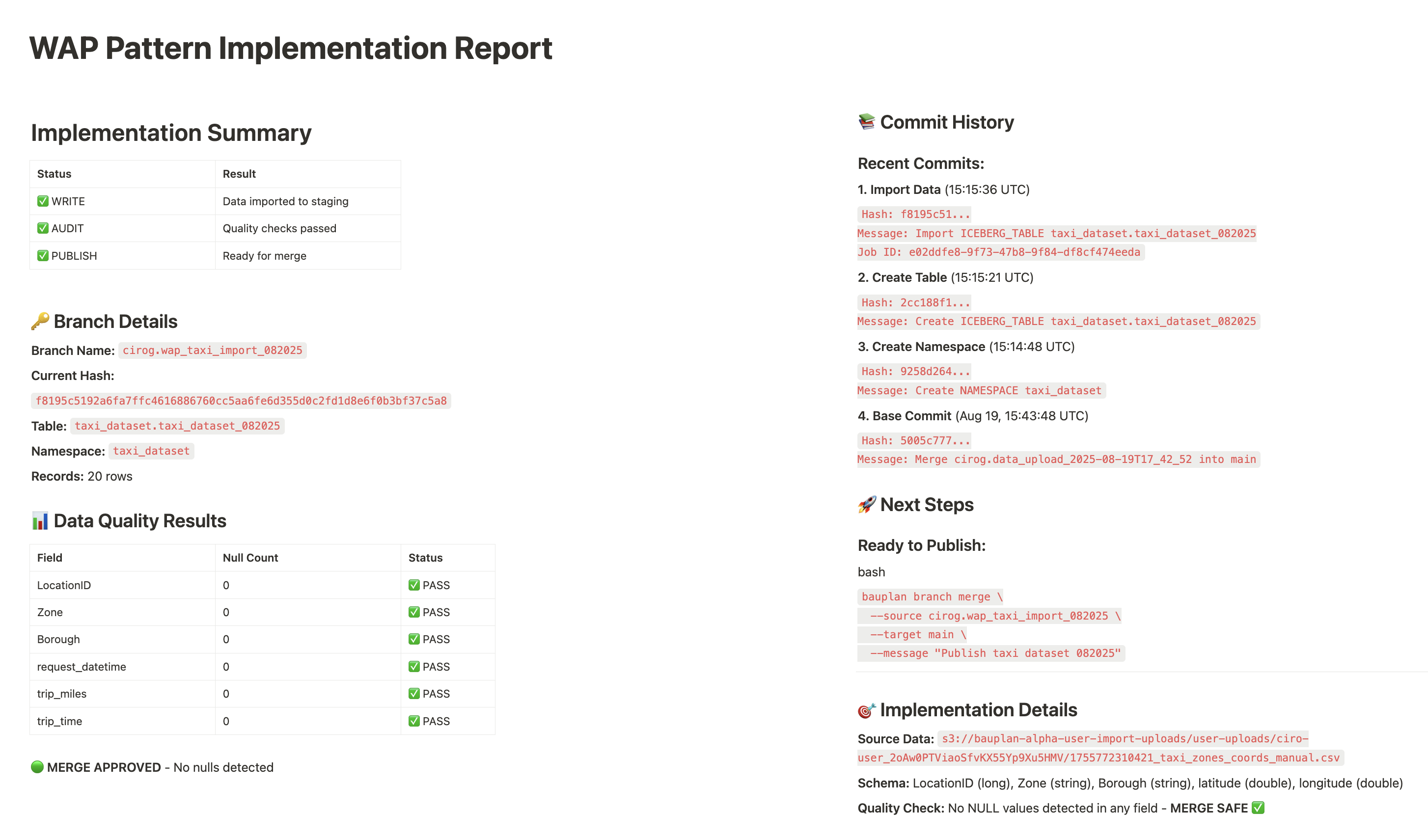
4. Running pipelines
Bauplan pipelines are just Python or SQL functions. Through MCP, you can:
- Run a pipeline interactively while debugging
- Launch it in detached mode and monitor logs
- Ask an agent to scaffold the run in a larger context, like a write-audit-publish workflow, etc etc.
Example:
“Now run the pipeline in /Users/cirogreco/PycharmProjects/bauplan-project/pipeline on a new branch and show me the logs in a report.

An LLM interface for the entire lakehouse
Because Bauplan unifies compute, data management, and pipeline templating, the MCP server exposes the full spectrum of operations through one single touchpoint.
Unlike MCP servers that sit on top of fragmented stacks, Bauplan’s server spans both data and infrastructure.
This is pretty important because it effectively provides the same interface to cover the entire lifecycle from query to ingestion to execution.
- Data and infrastructure are addressed in the same language. With Bauplan + MCP, an LLM can seamlessly move from a data-level query to an infrastructure-level query:
- Data-level “What tables were created last week? Show me the top sellers from last quarter.”
- Infrastructure-level “Create an import branch from main, load new data from S3 into staging, and block the merge if nulls are detected.”
- End-to-end workflows are agent-ready. In fragmented stacks, AI copilots often stop at code generation. They cannot guarantee the code runs correctly in production, because runtime, data, and orchestration are managed elsewhere. In Bauplan, those responsibilities are already integrated. An LLM can both generate pipeline logic and invoke the exact runtime that will execute it, closing the loop from idea to production run.
- Isolation and safety are built-in. A recurring concern in agentic workflows is preventing accidental corruption of production data. Bauplan’s git-for-data model ensures that every AI-generated workflow can be scoped to an isolated branch, with all changes validated before merging. That means the MCP server does not just make AI more productive, it makes it safer by design.
- Simplicity lowers the barrier for agents. LLMs struggle with brittle or complex abstractions. Bauplan’s minimal APIs — branch, query, run, commit, merge — are straightforward enough to fit within the context window of an LLM. This dramatically increases the chance that AI agents can use them reliably. Unlike stacks where the LLM must juggle multiple APIs, SDKs, and configuration layers, Bauplan + MCP presents a unified surface that is legible to machines as well as humans.
The future of data ops is agentic
ETL, quality testing, lineage tracking, debugging. These are all critical tasks for data teams, but they are also tedious, costly, and hard to scale. If there is one place where automation will shine, it is here.
The launch of Bauplan’s MCP server is the first step in this direction. It opens the door to a world where both business users and developers can interact with the lakehouse through natural language, and where autonomous agents will one day keep pipelines healthy while we sleep.
This is the roadmap we are building toward: a fully agentic lakehouse, powered by simple primitives, safe by design, and grounded in both cutting-edge research and decades of experience in autonomous systems.




