Write‑Audit‑Publish: Ship Data Safely, Move Faster


Introduction: What WAP is and why it matters
The first time I heard the term Write-Audit-Publish (WAP) was in a popular talk by Netflix in 2017 called “Whoops, the numbers are wrong! Scaling data quality @ Netflix”.
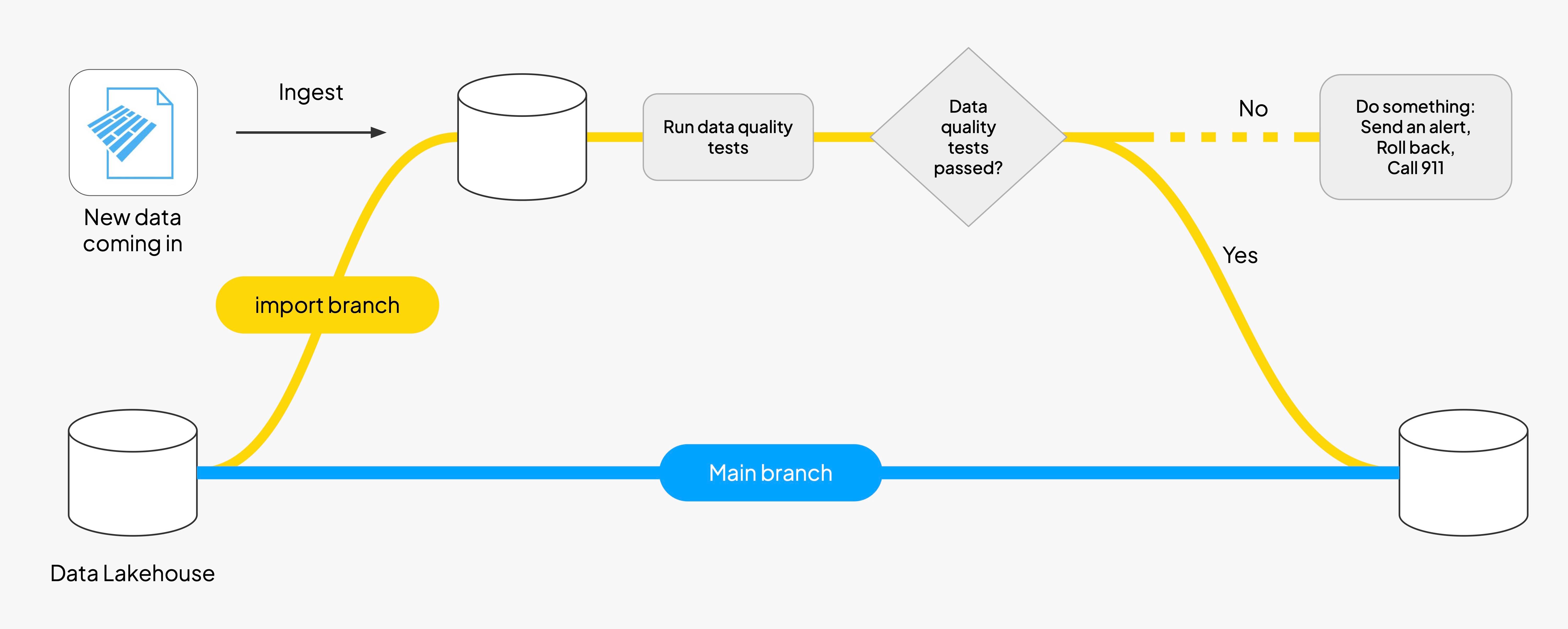
It is a simple idea with outsized impact: you write data changes in isolation, you audit those changes against quality and business rules, and you publish only what passes. In a nutshell you have three steps:
- Write: Data is initially ingested and written to a temporary staging area.
- Audit: The data undergoes quality checks, validation, and logging to ensure its integrity.
- Publish: Only data that passes the audit is merged into the main data branch for wider use and consumption by other systems.
It is unlikely that this concept was invented in 2017 for the first time, nonetheless we will use this terminology because it is used widely in today’s data engineering.
However you call it, it’s a three-stage process designed to ensure data quality and keep control of the release of data.
In real life, WAP is a very useful process design to avoid problems that we data engineers know all to well, especially when working at scale and with a lot of data sources. Because in data lakes, data is often a bunch of files with little (or zero) built-in version control, weak lineage, and fragile reproducibility, small mistakes like a schema drift right after ingestion propagate silently through data pipelines that span across many tables, tools, and languages.
If you worked on data pipelines in your life, you will recognize this:
- 12:10 AM: A small change lands in the main fact table. A new column, a tweak to a calculation, a backfill for last quarter.
- 12:18 AM: The writer starts updating partitions in place. A few succeed, one stalls, another fails on a type mismatch.
- 12:42 AM: Readers now hit a mixed world: some partitions have the new schema and logic, others don’t. Downstream joins begin to drop rows.
- 1:05 AM: A “staging” table exists, but there is no gate that prevents promotion. Someone points a dashboard to the half-updated source to “check quickly.”
- 4:30 AM: Overnight aggregations finish on inconsistent inputs. Nothing alarms because each table, taken alone, looks valid.
- 7:00 AM: Reports go out. Key metrics jump in ways no one can explain.
- 9:20 AM: “Why did revenue drop 31% overnight?”
- 10:40 AM: The team is rolling back snapshot by snapshot, table by table, trying to reconstruct the exact state before the change.
What failed in this story isn’t a single job, but it would have been easier to avoid if we had a WAP workflow in place: write in isolation, audit that change, and publish only after it passes (which in this case should not have been published).
Another way to put it is that data teams often live without the everyday safety net that software engineers take for granted. The world is a worst place because of it.
The key benefits of write‑audit‑publish patterns
Adopting WAP design patterns in data pipelines has several advantages:
- Quality by design. Changes must clear checks before they can influence production. Data that fails never becomes visible, so quality is enforced rather than inferred after the fact.
- Zero blast radius. Work happens in isolation. If something goes wrong, the impact is contained to a temporary branch and never hits dashboards, models, or downstream services.
- Predictable releases. Clear separation between writing, auditing, and publishing turns messy updates into routine deployments. Failures are easy to pinpoint and roll back as a unit.
- We can all go live our lives. Because validation is systematic, teams spend less time on triage and more time on development. Pipelines become easier to scale and evolve without rewiring everything.
- Trust and compliance built in. Without isolation and auditable history, every data change is a potential liability. A single unchecked update can silently break SLAs, trigger regulatory exposure, or corrupt the audit trail your business depends on. Enforcing controlled environments, explicit gates, and full lineage is necessary so you can prove to auditors, regulators, and your own leadership that nothing unvalidated ever reached production.
This is the practical value of WAP: safe iteration, fast feedback, and a release process that remains robust even as your lakehouse grows.
If it so cool, why I am hearing about it just now?
Even though WAP has undeniable advantages, it is still not widespread. The reason for this is that our current tooling does not provide data developers with simple ways to implement it.
If you ask practitioners why they tried WAP and backed away, you hear similar themes:
- Integration tax. The “reference” pattern stitches together a table format, an orchestrator, an expectations library, and a catalog. Each tool is great at its slice, but the gaps in between are your team’s glue code.
- Double work, double cost. Quality gates frequently run after data is written, which means you compute and store results you might later reject. Teams experience audits that take as long as the original transformation.
- No real transactions for pipelines. A “staging” table is not a true environment. Without branch‑level isolation, partial updates and mixed schemas still leak into whatever is reading data (more on this below). Moreover, orchestrators like Airflow schedule tasks but cannot guarantee all‑or‑nothing publication across multiple tables, so “publish” quietly becomes “best effort.”
- Brittle checks, noisy alerts. Rules live far from the code that produces the tables they check. They go stale, fire false positives, and get ignored.
- Rollback theater. When the model for change is per‑table rather than per‑run, “revert” turns into a manual hunt across snapshots trying to reconstruct state.
Bauplan’s Git‑for‑Data: the foundation for WAP everywhere
One reason WAP has been so hard to adopt in practice is that most data platforms don’t speak the right language. They give you tables, jobs, and schedulers — but not the primitives that make isolation, validation, and controlled release effortless.
That’s where Git-for-Data comes in. By treating your lake like a version-controlled codebase, Bauplan encodes the semantics you actually need to make WAP the default way of working. Instead of gluing tools together, you get the same verbs developers already know — branch, commit, merge, rollback — applied directly to data.
- Branches to isolate any change. Create zero-copy branches of the lake that look and feel like production but are safe to modify.
- Commits and history to group multi-table edits into traceable, auditable units.
- Merges that publish changes only after validation.
- Rollbacks that revert a whole run across all affected tables.
Under the hood, table-format primitives handle snapshots, schema changes, and ACID at the table level. Bauplan layers a catalog-level operational model on top, so pipeline-wide changes move together with one mental model: branch → test → merge.
Bauplan brings Git‑style semantics to your lake so WAP becomes the default way you work.
WAP everything
Each primitive of git-for-data maps directly to a part of the WAP cycle, so you can branch, test, and merge with the same ease as pushing code to GitHub.
1) Zero-copy branches. Need a safe place to test an upstream schema change or import a new dataset? In Bauplan, every branch is a zero-copy clone of production. It feels like you have infinite environments, but without doubling storage costs. Engineers can run experiments on the full dataset, not a synthetic sample, and know exactly how changes will behave.
2) Expectations and quality tests at runtime. Silent schema drifts and type mismatches are what make 2 AM incidents. Bauplan runs expectations as part of the pipeline run, before tables are even committed. You can use the standard expectations library (expect_column_no_nulls, expect_values_in_set) or your own Python/SQL checks. If anything fails, the run halts and nothing bad lands in production.
3) One API for the full flow. Instead of juggling separate tools for staging, validation, and orchestration, Bauplan gives you a single API. Create a branch, import new data in it, run your pipeline with expectations, and merge only when everything is green. The whole end-to-end cycle is just a few lines of code.
4) Transactional publish and instant rollback
Merges are all-or-nothing across the catalog. If your pipeline touches five tables, they either all pass and publish together or none do. That means no half-updated states for downstream readers. And if you ever need to revert, a single command rolls back the entire commit across all tables — like hitting “undo” on your lakehouse.
WAP in pipeline design
I don’t really know why, but most of the explanation of WAP out there focus on data ingestion and staging locations to write that data before importing it in the production data lake. That is not wrong at all, it’s just one application of this design pattern.
Modern data work is built around pipelines, like DAGs of data intensive jobs that pull, transform, and load data across dozens of tables. The problem is that pipelines don’t have transactional guarantees out of the box. If one step fails, you can be left with half-updated tables, corrupted joins, and dashboards showing nonsense before anyone realizes.
Fixing this problem is left to the data engineering team and it is a lot of work.
Think of a pipeline that needs to compute some kind of concept needed by the business for analytics purposes, like the “browsing sessions where the user bought something”.
The pipeline will have multiple steps. It will probably read and write to several tables, like , user_clicks, page_views, add_to_cartst , compute some intermediate concept and write it like user_sessions and eventually rolls up into a final table that powers a dashboard the marketing looks at every day. If step three dies after steps one and two, half the tables are updated and half are not. Downstream consumers see a broken world.
Because business logic cuts across tables, consistency has to apply to the whole pipeline, not just one table at a time. Without that, three failure modes keep showing up:
- Partial failures. A run crashes mid-way, leaving some tables new, others old. Single-table ACID can’t protect the workflow.
- Concurrent DAGs. Two jobs touch overlapping tables at the same time. One silently overwrites the other.
- Rollback headaches. You discover at 9AM the run was bad. Now you’re rolling back table by table, hunting snapshot IDs.
Nobody would accept a database that updates only half a row. Yet, we tolerate pipelines that update half their outputs. WAP implemented with Git-for-data closes that gap by treating the entire pipeline as the unit of consistency: write in isolation, audit as a set, publish only when everything passes .
Conclusion: why this design makes WAP feel simple
The value of WAP isn’t just technical neatness: it’s business impact. When the platform bakes in the right semantics, shipping data becomes as safe and repeatable as shipping code.
- Isolation as a primitive. Zero-copy branches mean every change is tested on production-sized inputs without touching production. Safe iteration accelerates velocity.
- Validation in the write path. Expectations execute before data lands, so you avoid wasted compute, bad reports, and the cost of chasing false alarms.
- Transactional publish across the catalog. Entire change sets go live together, so your dashboards and ML features never see a half-updated world.
- One mental model. Branch → run tests → merge → rollback. Simple verbs anyone on the team can learn.
Ready to see how this works in practice? Bauplan makes WAP the default workflow with Git-for-Data primitives that turn complex data deployment patterns into simple Python commands. See WAP workflows in action with zero-copy branches, automated quality gates, and atomic merges.
For leaders, this translates into fewer production incidents, faster deployment cycles, and a level of trust in data that supports business decisions. For engineers, it means spending less time firefighting and more time building.
When these guarantees live in the platform, WAP stops being an aspirational pattern and becomes the default way to work. That’s the difference between “we tried and removed it” and “we ship safely, fast, every day” .




