Shift left with Iceberg - Bauplan & Trust & Will


“Some time ago, Trust & Will built a Modern Data Stack (MDS) around Snowflake and dbt to power analytics and business intelligence. Trust & Will built a Modern Data Stack around Snowflake and dbt to power analytics and BI, like most MDS stacks. Over time, this warehouse-centric design became a bottleneck. Most transformations, tests, and backfills competed for the same compute. Small schema changes required coordination across multiple dbt models, driving up costs and complexity. With all data confined to the warehouse, the team had limited flexibility to use other engines and languages for Python- and AI-driven work: the work either happened separately from the data or not at all. Looking ahead to an agentic future, they needed a warehouse that is durable, functional, idempotent, and replayable from day one, flexible enough to evolve without sacrificing reliability. The answer was a data lakehouse: open storage, reproducible transformations on Apache Iceberg, and safe deployment via Write–Audit–Publish gates. We paired this with a unified environment for transformations and testing, end‑to‑end visibility across pipelines, and a leaner Snowflake footprint delivering a Data Factory’s quality‑first operating model without months of bespoke platform build‑out. So this is why we chose Bauplan.

Shift left made simple
Implementing an open lakehouse on Apache Iceberg has clear advantages: moving data from a warehouse to S3 gives teams control, lower costs and a simpler design than the MDS. But it also removes the convenience of an integrated environment where compute, testing, and monitoring can coexist behind one interface.
To rebuild that, companies usually face two choices:
- DIY and wire together catalogs, schedulers, compute engines, and governance layers.
- Enterprise platforms, like Databricks, which will offer it all but forces you to live inside their ecosystem.
Bauplan offered a third option. A code-first lakehouse platform where those capabilities are built in. It lets engineers define declarative pipelines, manage Git-style branches, and run data quality checks inline, all in Python and directly over object storage.
At Trust & Will, this setup is complemented by Orchestra, which handles orchestration, monitoring, and lineage. Unlike general-purpose schedulers, Orchestra understands data semantics and integrates natively with Bauplan’s runtime, so tasks, dependencies, and tests remain synchronized in one control plane.
Together, they allowed Trust & Will to run Iceberg in production with the simplicity and confidence of a managed warehouse, i.e., open, testable, and fully under their control.
From Warehouse Workflows to Open Storage
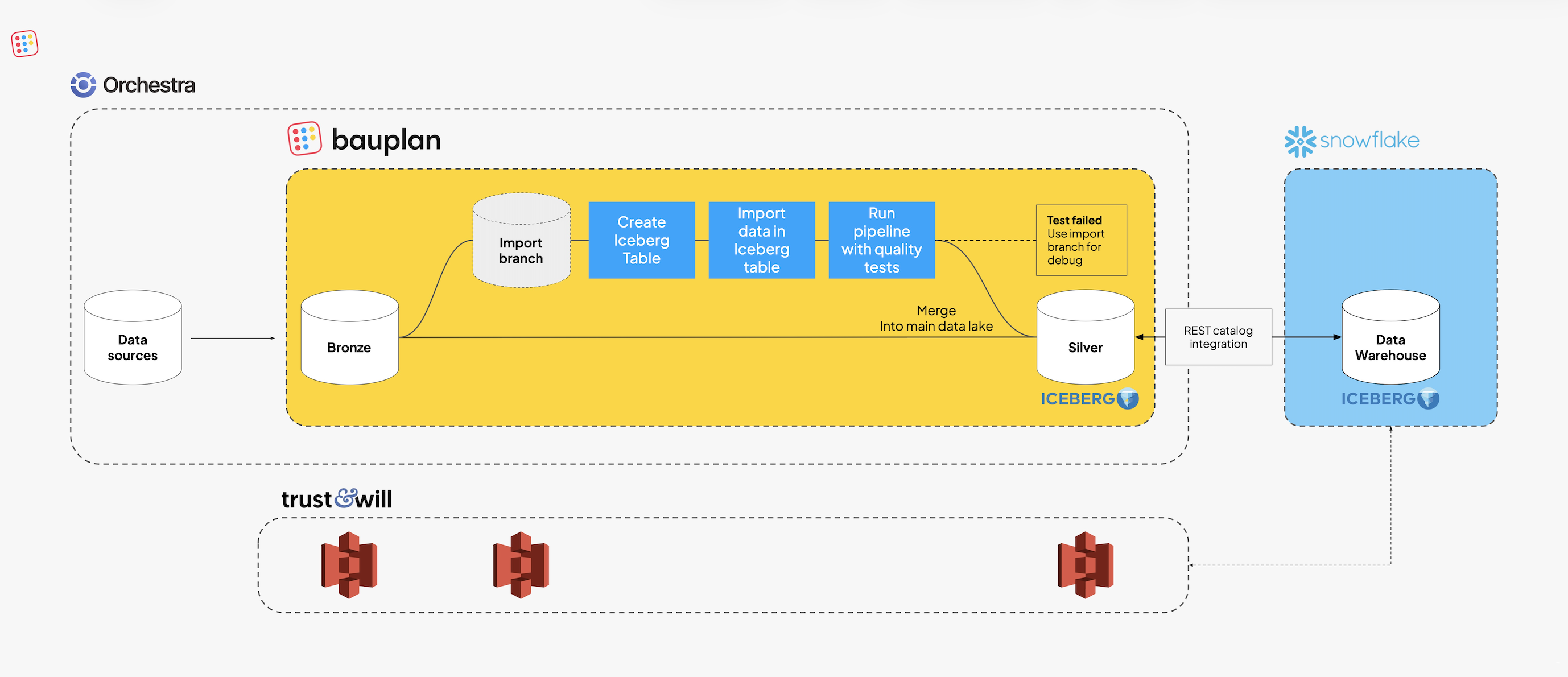
Trust & Will began by moving raw and intermediate data to S3 in Parquet, establishing a clean separation between storage and compute.
Instead of running every transformation through the warehouse, they defined them directly in Bauplan as Python or SQL models. Each model declares its inputs, logic, and outputs, while Bauplan handles packaging, dependency resolution, and execution on isolated, serverless compute.
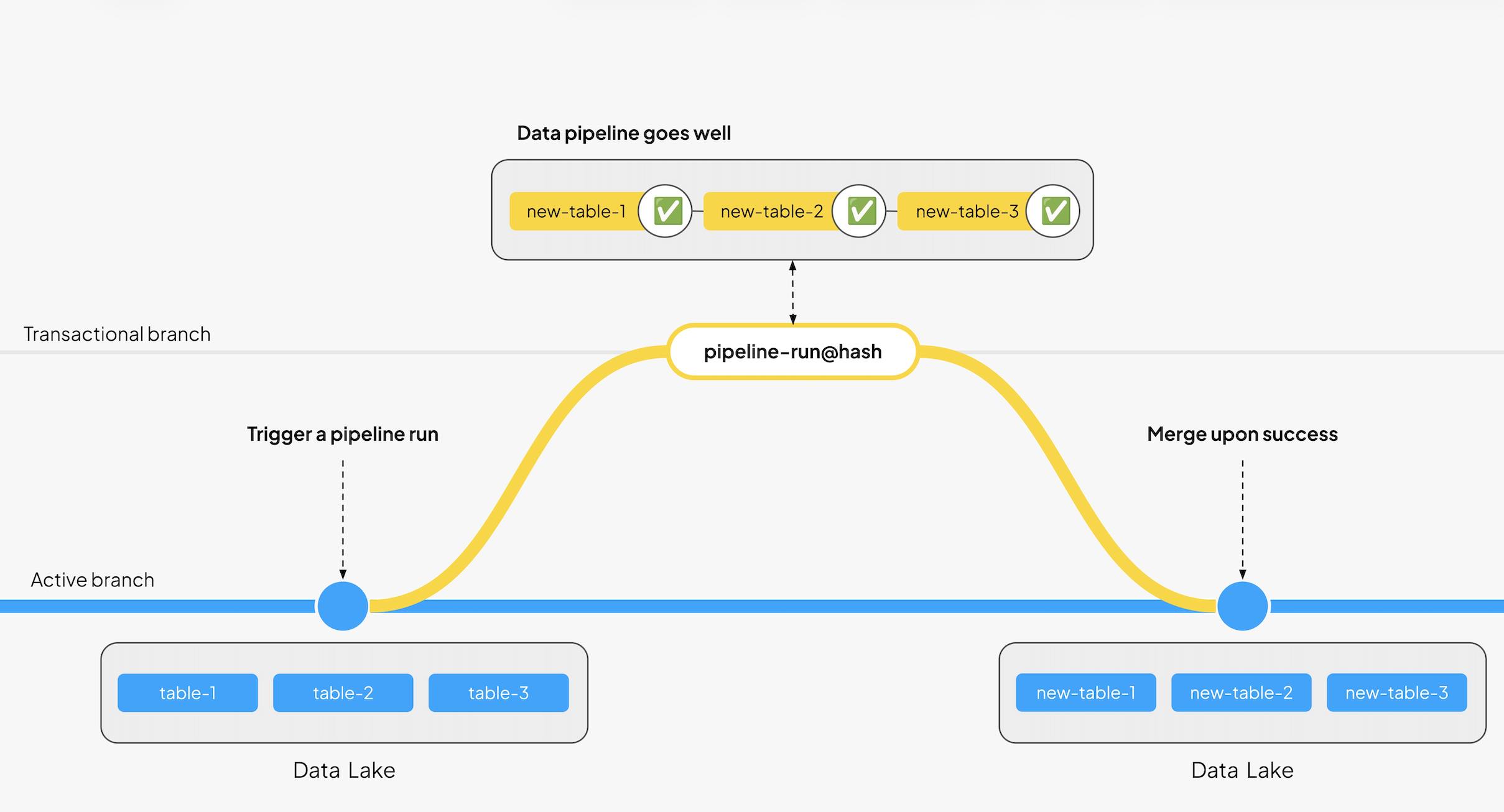
At the heart of each workflow is Write–Audit–Publish (WAP), the pattern Bauplan uses to guarantee correctness:
- Write: create or update data in an isolated branch.
- Audit: run data quality expectations at runtime.
- Publish: merge changes atomically when all checks pass.
Each merge creates a new Iceberg snapshot. If a test fails, nothing is published. Every version of every table is reproducible and can be diffed or rolled back instantly. This replaced post-hoc validation jobs with inline, runtime guarantees.

Implementation
Is it hard to implement? Not really, all can be scripted in a very simple Python logic.
This script shows how Trust & Will’s ingestion jobs run entirely as Python code, orchestrated by Orchestra and backed by Bauplan’s lakehouse runtime.
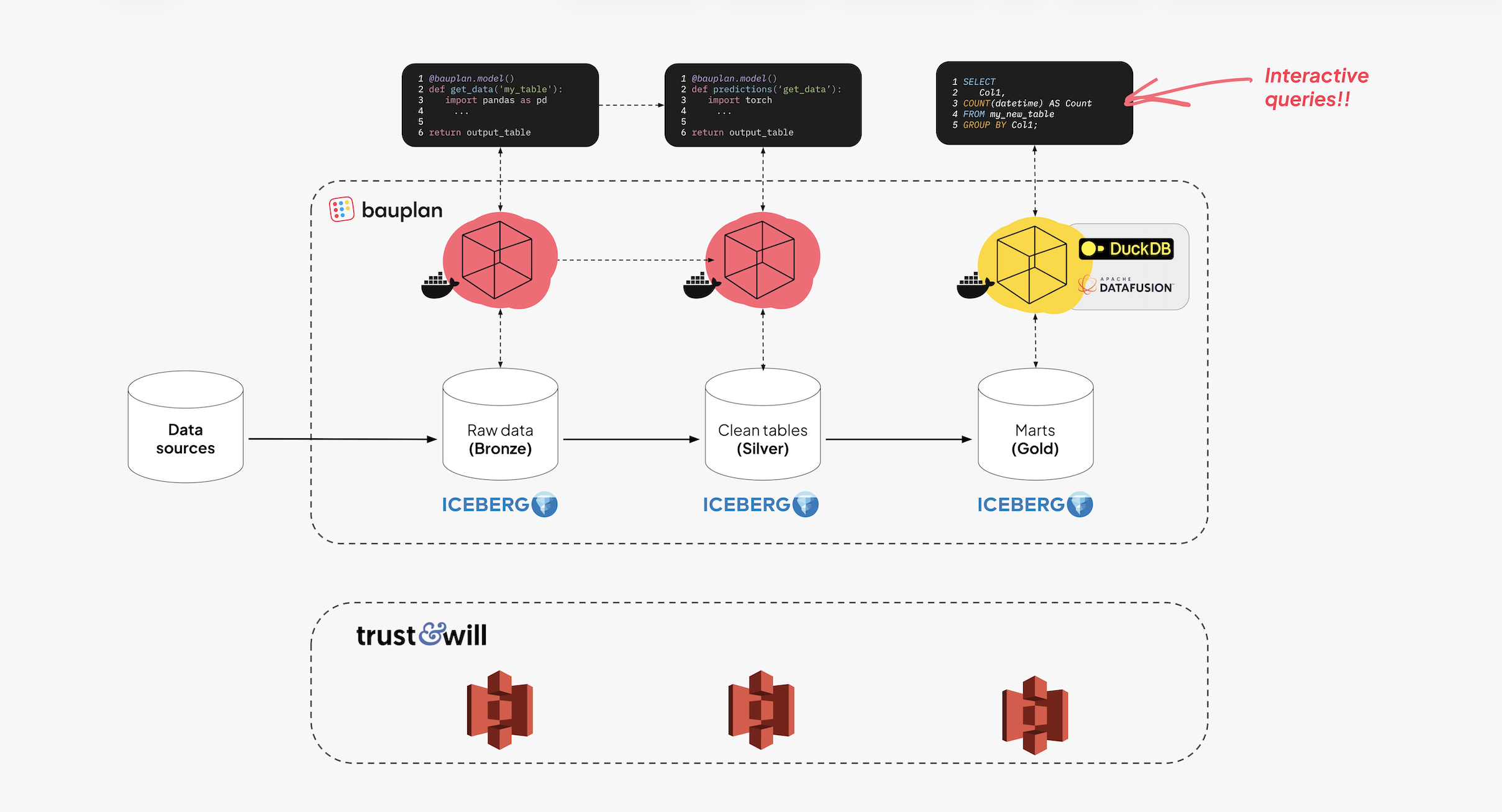
Data is processed in-memory using Apache Arrow, the columnar format shared across Bauplan’s execution and query layers. Arrow enables the same representation to be used for transformations, testing, and downstream analysis (i.e. without serializing between engines).
Shared Compute for Pipelines and Exploration
Bauplan’s compute is unified and multi-language, supporting SQL queries as well as Python functions. The same pool that runs pipelines also serves interactive queries and BI. BI tools connect through Bauplan’s PostgreSQL-compatible proxyin read-only mode, so dashboards hit Iceberg tables on S3 without copies. Configure host and port, set the database to the Bauplan branch/ref, use an API key as the password, and the key’s user as the username; enable SSL. JDBC clients must set preferQueryMode=simple.
This shifted exploratory and reporting workloads off Snowflake while keeping Snowflake attached at the end via external Iceberg tables for gold models. Data lives once in open storage and feeds pipelines, notebooks, BI, and AI.
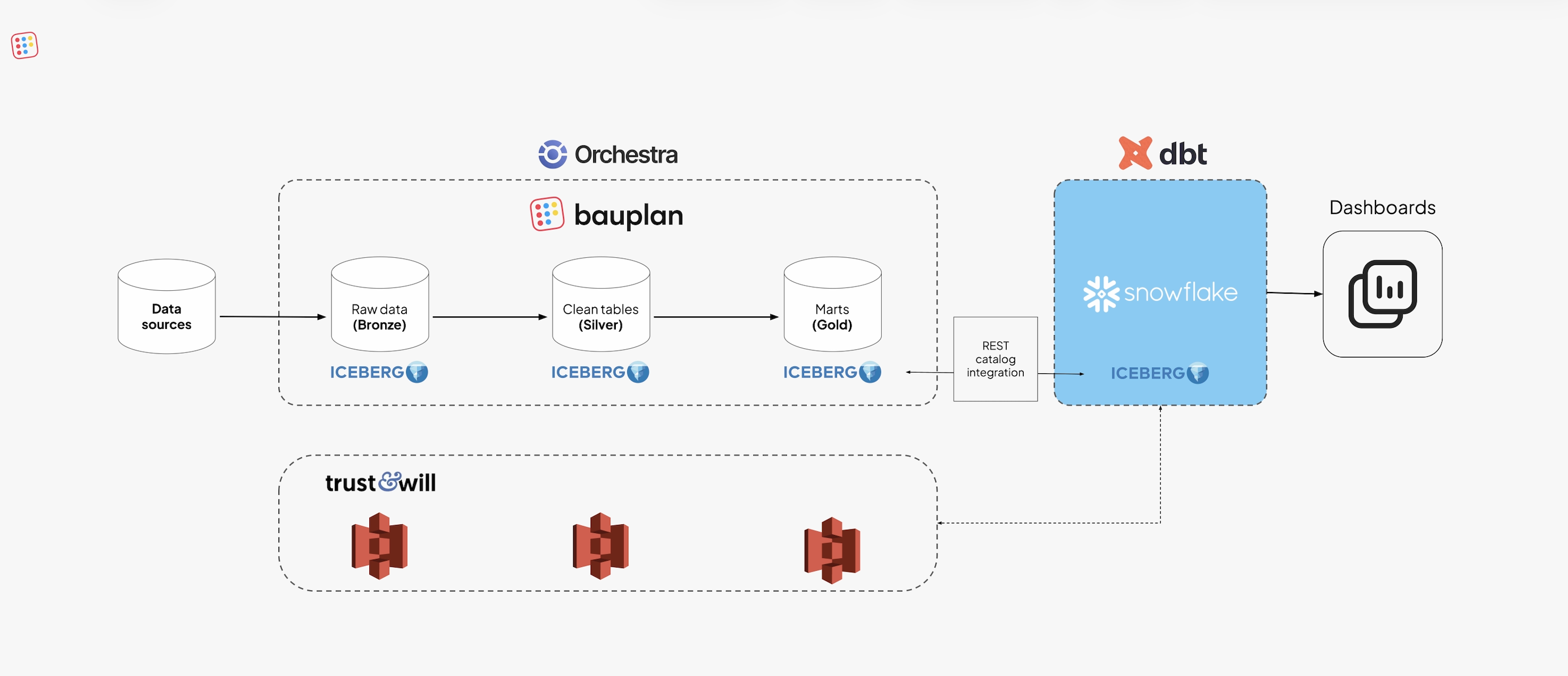
Snowflake as the Serving Layer
Many of the company’s gold-layer models will still run in dbt on Snowflake. Rather than replace them, the team connected Snowflake to Bauplan’s Iceberg catalog. Using Snowflake’s Iceberg REST integration, external tables point directly to the same objects managed by Bauplan.
This will keep analytics unchanged while shifting storage and transformation logic to open infrastructure. Snowflake reads data in place while no duplication or ingestion is required.
Orchestration and Lineage
Workflows are scheduled through Orchestra, which executes Bauplan tasks and tracks lineage.
Orchestra provides observability and alerting; Bauplan provides compute and data semantics.
The integration gives engineers a full view of dependencies from ingestion to BI without manual coordination.
Toward a Broader Platform
The lakehouse now serves as the base for new automation and AI work.
Because Bauplan runs native Python, the same environment can host data-driven agents and model workflows without new infrastructure.
Future iterations will extend this pattern: data, code, and AI processes sharing the same declarative runtime.
Bauplan made it possible for Trust & Will to build a production-grade lakehouse with minimal overhead: open, reproducible, and safe.




