Data Engineering is Becoming Software Engineering (And that’s a good thing)


Data in 2025 is different from what it was only five years ago. The rise of AI has forced data teams to be more involved in user-facing features, not just internal reports.
This fundamental shift pushes data engineers to adopt the same safety nets and best practices software engineers have been using for decades.
We just published a post about Write-Audit-Publish patterns in data engineering, because that is a use case that is extensively supported by our platform.
Having said that, the description of that use case is about something bigger. It's about data engineering becoming more like software.
The Moment Everything Changed
Back in 2017 we built a company that was providing ML capabilities for search and recommendations (that was before NLP was an API call and RAG systems became fashionable).
Most of our friends were also in ML and Data Science (it was the sexiest job of the 21st century, remember?), and for most of them the job consisted in working ad hoc sophisticated analyses on notebooks.
Analytics lived in warehouses and served a few internal stakeholders who could only have a limited number of reports and sometimes Tuesday's numbers might be wrong.
Our world was different because for us data workflows were part of software applications, like a search and recommendation engines for e-commerce or real-time analytics dashboard embedded in the admin console of our a b2b platform.
Compared to those years, more data teams transitioned to building data intensive applications, like recommendation engines driving revenue and engagement, fraud detection systems protecting customers and so on.
Plus, AI happened: RAG applications and conversational agents became ubiquitous because they are much easier to build and infinitely more effective thanks to pre-trained models.
Compared to early days of data science and analytics, data today is the engine of customer-facing features.
When your data pipelines break, important stuff stops working. When your vector database gets corrupted, customer support breaks. When your feature store has bad data, your personalization engine starts showing users the wrong products.
The stakes changed completely. But a lot of our tools and practices in data engineering didn't.
Software Engineers Figured This Out Decades Ago
Software teams learned this lesson pretty early. Because software applications drive so much value, they couldn't ship broken deployments and fixing them in production. The customer experience too important and the business impact is too high.
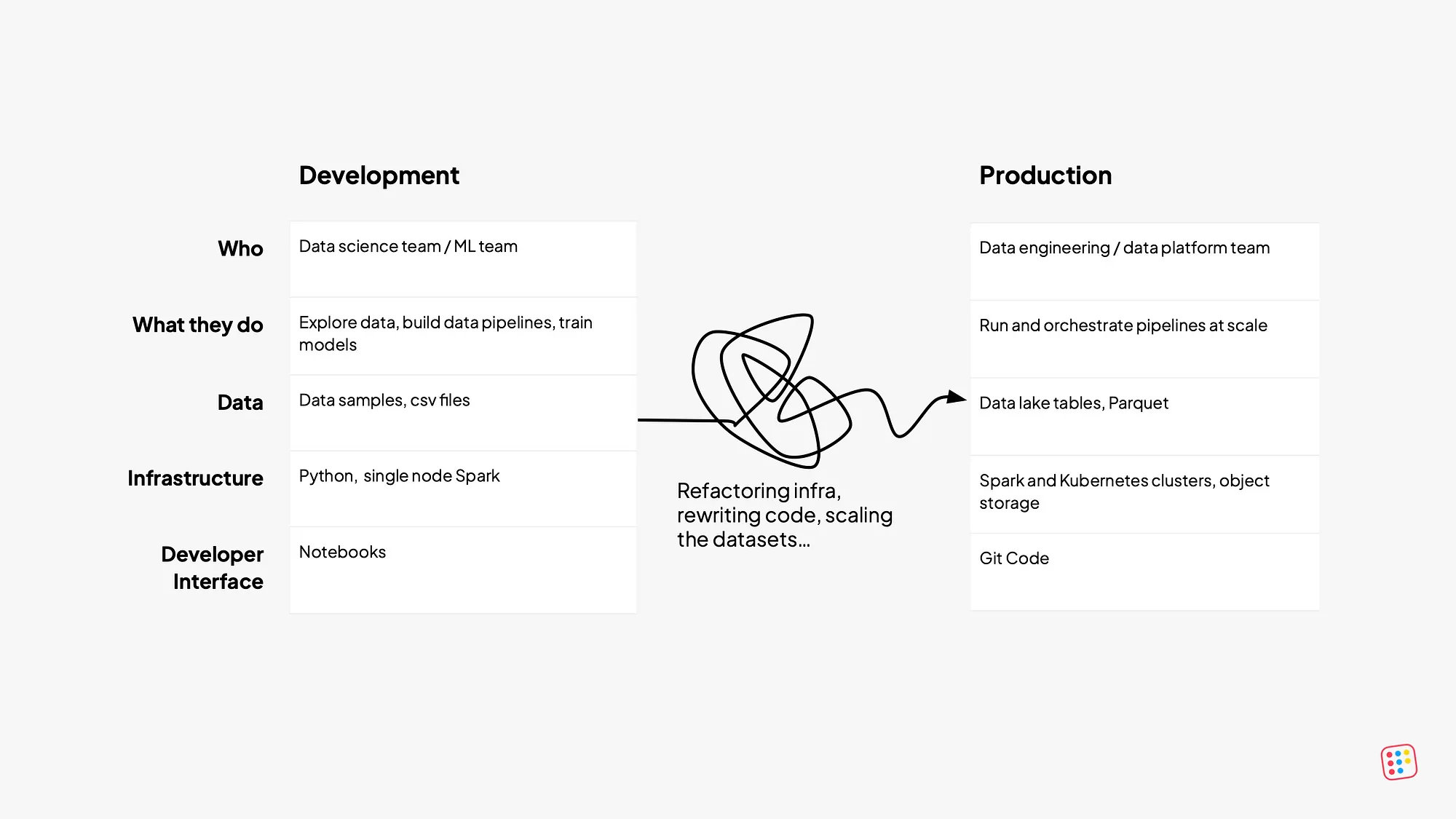
So, they came up with best practices to iterate fast and securely: version control, isolated development environments, comprehensive testing, and CI/CD.
Data engineering never had the same environmental pressure. Until now.
Here's what's fascinating: when you look at what data teams actually need today, it's almost identical to what software teams built years ago. Isolated environments to test changes safely. Atomic deployments that update all components together. Version control that lets you roll back entire releases instantly. And above all: simple abstractions that are easy to learn and maintain over time.
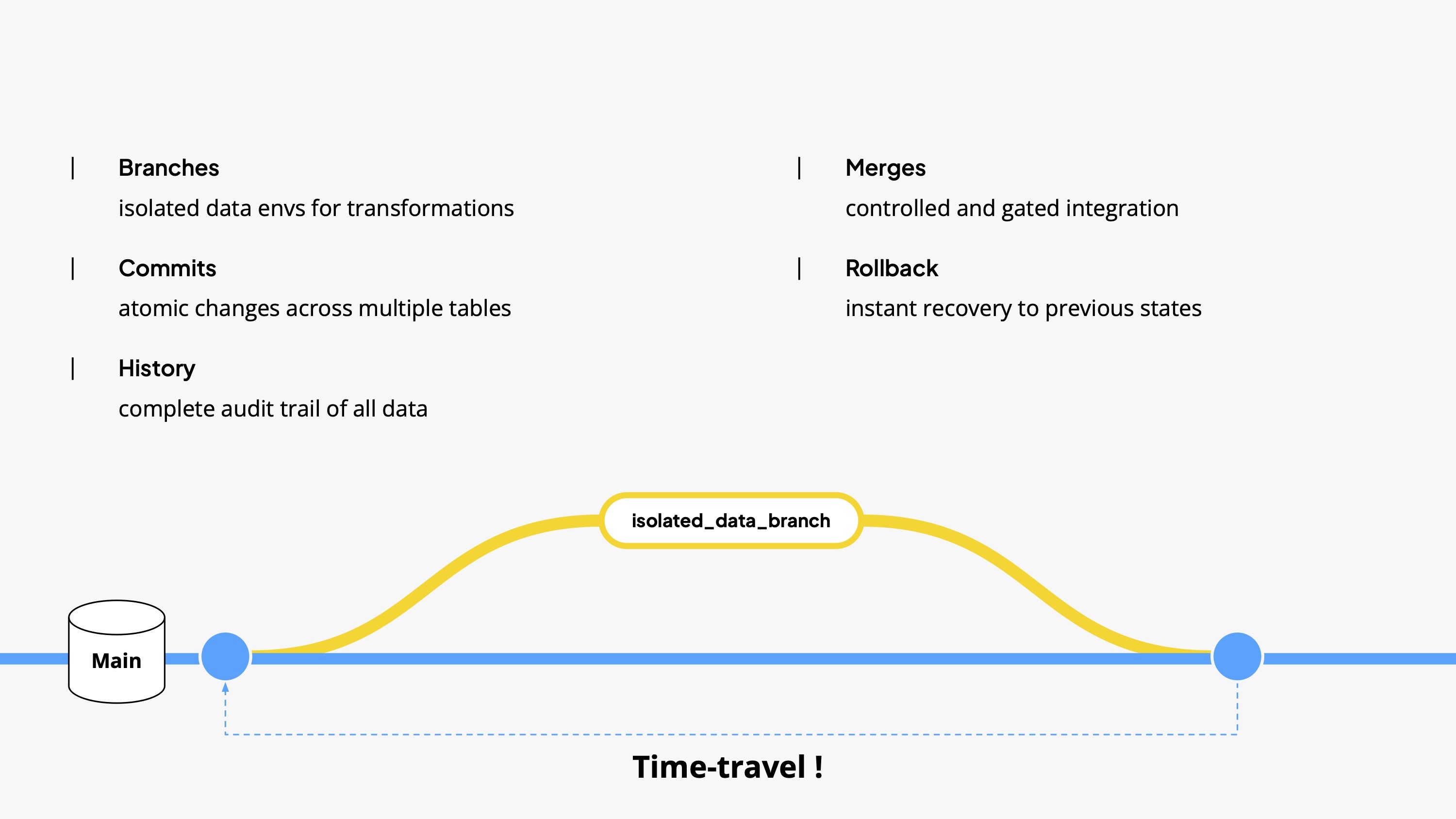
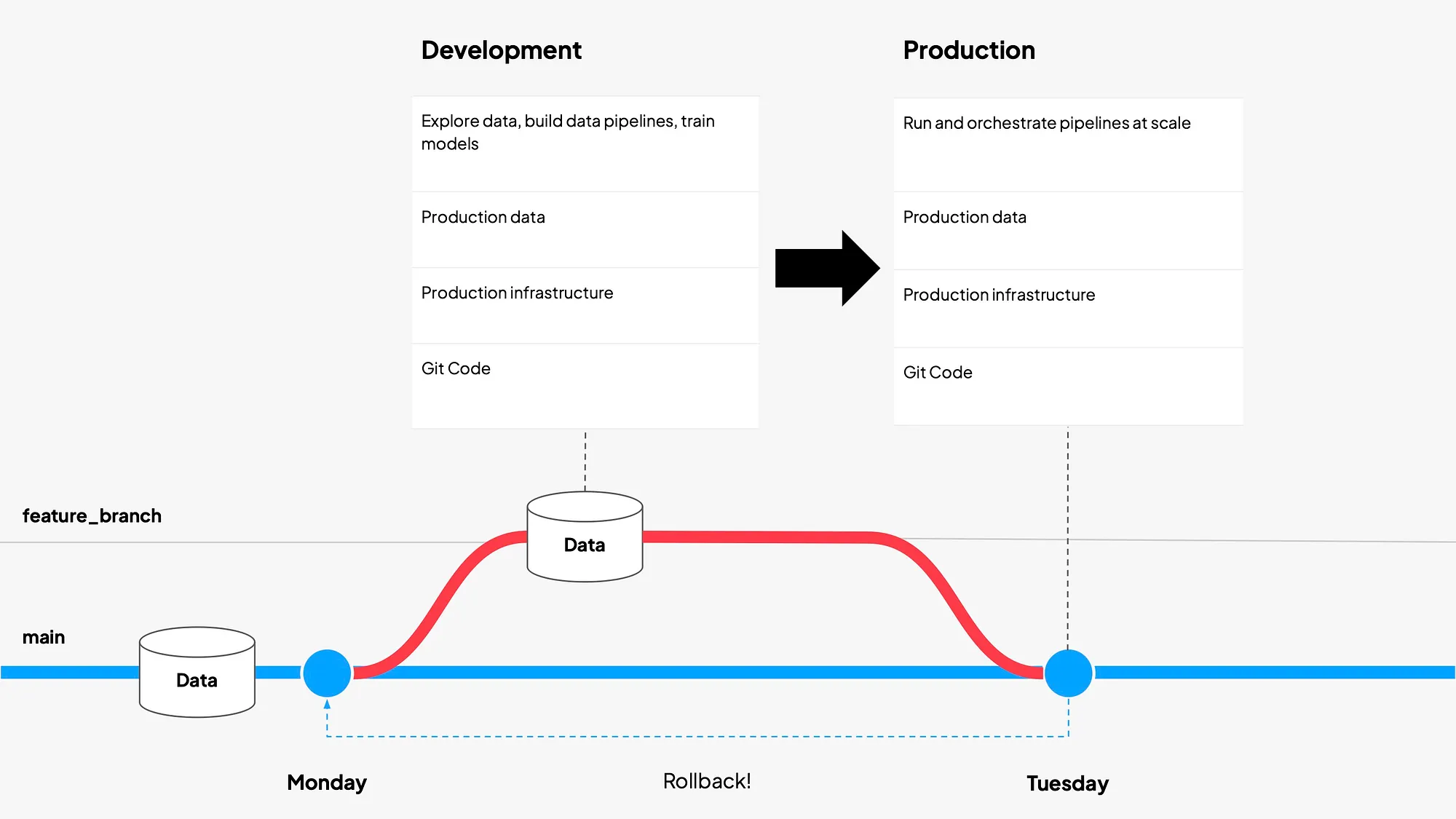
Write-Audit-Publish is a perfect example of this convergence. You can think of it as blue-green deployment for data. Changes are written to an isolated branch, audited with automated tests, and only published if they pass, ensuring that bad data never leaks into production. The result is that data is more dependable, deployments are safer, and in turn experimentation is easier. Shipping data becomes as reliable as shipping code. The pattern itself isn't new. Netflix described it in 2017 and as far as I know introduced the name, but data engineers used staging environments for their data way before that.
The point we want to make is that, even if it a undeniably useful design and it has been around for a while, it's only becoming practical now because platforms are finally providing the infrastructure primitives to make it simple.
Especially in analytics, where your data stack is much more fragmented than vertical databases, it is hard to find platforms that makes it easy for data developer to:
- create isolated staging environments for entire pipelines (easily, not by taping ten things together).
- deploy changes atomically across our entire data lake, so partial pipeline failures don't corrupt downstream tables in weird ways.
- back complete pipeline runs with a single command, because very often data fails silently - like it seems everything is ok because the pipeline ran, but the data are wrong.
What This Means for You
These needs were very clear to us when we were working in startups. At the time we were building very differentiating features around AI search, recommender systems, and embedded analytics - and all of them came out of various forms of complicated data pipelining.
Now, the same needs pop out is everywhere. One European broadcaster we work with went from 8 months to get ML models into production down to 3 weeks. Their developers ship directly, no platform team in the middle.
The lesson isn’t just about speed. When deploying data changes feels as safe as deploying code, also the culture shifts. Teams experiment more, try more ideas, and recover faster when something breaks. That’s what continuous deployment did for software and now it’s happening in data.
For startups, this is even more pressing. If you are a fast moving startup, you don’t want to staff a platform team early on to build infrastructure that looks like every other company’s.
You would much rather have developers to be focused on the things that make your product different and your head of data embedded in your product team as much possible.
Your data platform should abstract away all the infrastructure and provide safety and reproducibility out of the box, so your developers can use data to build differentiating features without having to go through a data platform team. The infrastructure exists today, the patterns are proven, and the teams adopting them are already reaping the benefits. The real question is whether you’ll get there on your own terms, or because competitive pressure forces you to.
The Broader Pattern
As data becomes more central to customer experience, data engineering naturally inherits the same requirements that shaped software engineering: reliability, reproducibility, rapid iteration, and safe deployment.
Data teams are adopting version control for datasets, CI/CD for pipelines, and infrastructure-as-code for data platforms, so they can do much more with much less.
The entire discipline is converging toward software engineering practices. And that is a good thing.
We wrote about the technical details of WAP implementation in our deep dive on WAP patterns.
If you're curious about what this looks like in practice, watch our demo to see Git-for-Data workflows in action. Or dive into the technical documentation to try it with your own data.




