Your First Lakehouse


When a platform becomes inevitable
As you awoke one morning from uneasy dreams, you found yourself in need of more than your application database to work with your data.
Typically, this will happen when you start seeing one or two of the following symptoms:
- Workload scale: You’re scanning hundreds of millions of rows (or more) for common queries, and full-table/large partition scans are routine and your Postgres takes hours where an OLAP engine would take minutes.
- Latency under real concurrency: Your P95 query times keep drifting up over months, especially with tens of concurrent users and tripled in then last three months.
- Query shape/complexity: Your product asks for features that need queries with 5+ historical joins, CTEs and window functions.
- Data sources are multiplying: you have several databases buried inside products that you use to run your business (e.g a CRM, a lead generation tool, Google Analytics and a payment system) and you want to join them.
- You are shipping AI features: You product depends on AI features like RAG and conversational agents that require fresh and dependable to be prepared in data pipelines.
Time for a proper data stack ; a place where all that data lands, is shaped, and can be trusted to power analytics, ML and AI applications. In 2025, this means that you should get yourself a Data Lakehouse.
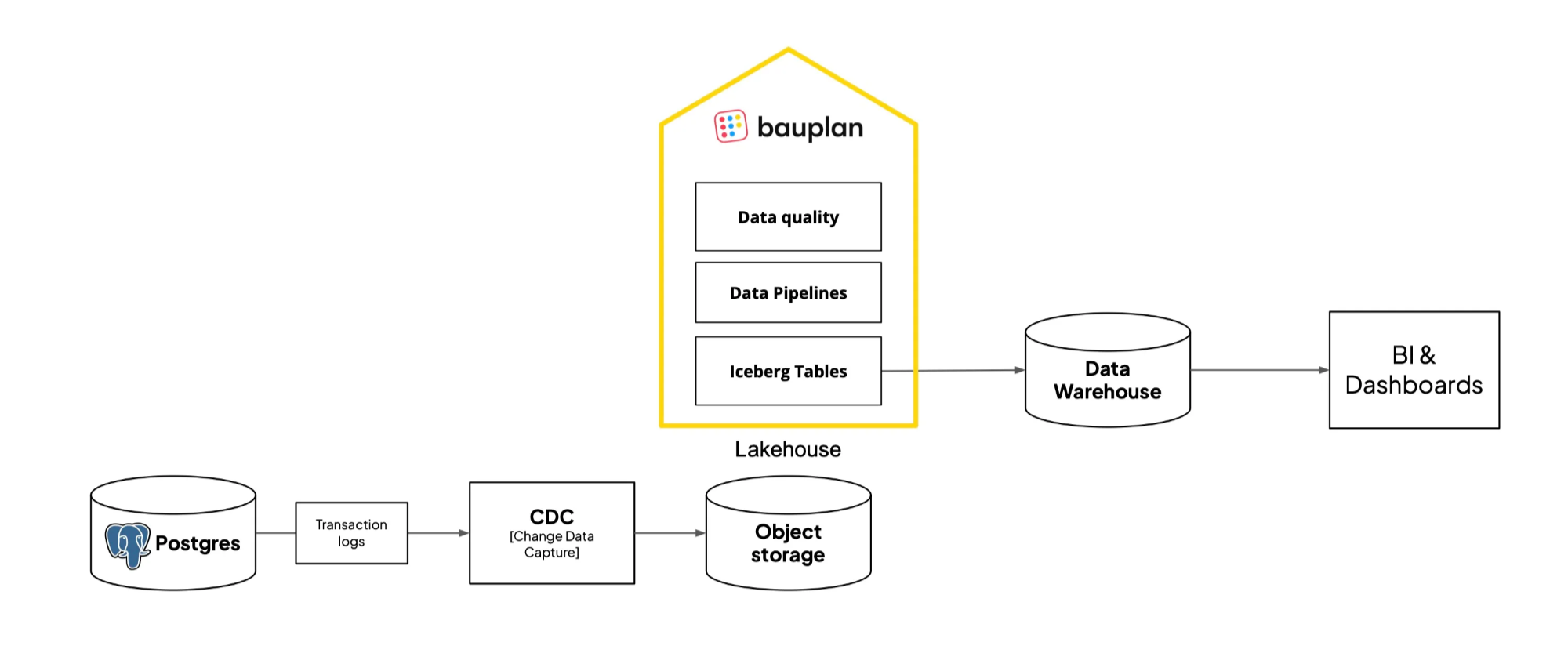
The first practical step is usually Change Data Capture (CDC): streaming changes from your operational databases into object storage. CDC gives you a fresh, append-only record of what’s happening in your business without overloading Postgres or MySQL. From there, you can start layering table formats, transformations, and queries. We wrote a separate post on how to set up CDC for a lakehouse.
The Data Lakehouse
A few years ago, data platforms centered around data warehouses. Data warehouses work well for BI, but fail to support Python-based use cases which have become central in the AI era. Moreover, they don’t support unstructured data and require you to move data inside of them, locking you in.
A different architecture called Data Lakehouse rose to prominence over the past few years to solve these problems. The core idea of a Data Lakehouse is to store data in your Object Storage as interoperable open table formats, while de-coupling the query layer. This allows for the performance of a Warehouse with a much more flexible, affordable and future proof data layer.
Today, the Lakehouse is considered the industry gold standard: it is the best way to move beyond your operational database and into analytics, ML and AI.
Your first data Lakehouse
When it comes to your first Lakehouse, you basically have three choices.
Build you own house
Brick by brick, by yourself, no architect. You pour concrete, wire pipes, curse at contractors, and months later you might have the house of your dreams but you might also be living out of an Airbnb.
The reference architecture is minimally composed of:
- cloud object storage (e.g. AWS S3),
- a open columnar format for file storage (e.g. Parquet),
- an open table format for transactions,
- schema evolution and time travel (e.g. Iceberg),
- a catalog for governance and discoverability,
- a compute layer to support SQL (e.g. AWS Athena),
- a compute layer to support Python (e.g. Kubernetes),
- a way to orchestrate processes that touch all of the above (e.g. Airflow).
In other words, assembling a Lakehouse from spare parts requires months of work and years of maintenance, while bringing no differentiation whatsoever to your business.
Buy a mansion from Databricks
Move into a full baroque palace with six hundred rooms, a ballroom and three chapels. It’s magnificent, every ceiling is painted, but every door has a key, and you can effectively get lost on your way to the bathroom.
Managed platforms like Databricks are extremely powerful: they cover the full spectrum of workloads from data engineering BI to machine learning, offer enterprise-grade governance and security, and scale to some of the largest data volumes on the planet.
However, they come with trade-offs. They are feature-rich, expensive, and designed for complex enterprise needs. At the same time, they don’t always make it easy to apply standard software practices: things like version control, testing, composition, or debugging often feel bolted on rather than native or require extensive work to implement. Furthermore, these platforms typically run a multitude of services in their own infrastructure, so before adopting them it is better to make clear whether it makes sense to commit to their ecosystems long-term.
The truth is, if you’re a Fortune 500 with thousands of users, dozens of teams, and compliance requirements at every turn, they’re a great fit. If instead you are a lean engineering team at a fast-growing company and you have a a small data team that needs to support a bunch of product-oriented developers, these platforms are probably not for you.
Move into a modern house
The third is what we set out to build, which closer to Le Corbusier’s Villa Savoye. It’s modern, minimal, a bit austere but meant to be lived in. Not lush, but complete and functional and with a slick minimalist design. You can move in today, and if one day you need more, the foundation is solid enough to expand.

We believe there’s a huge hole in the market for high-leverage engineering teams at fast-growing companies who treat data like software, don’t want to hire a platform team (you might even be a “one-person data platform team”), and need to move quickly without sacrificing reliability. That’s why we built Bauplan and yes we want you to choose us as your Lakehouse platform.
But this post isn’t only about us. In building the platform and working alongside our customers, we’ve learned a handful of design principles that make a first Lakehouse practical.
They apply no matter what tools you end up using. Think of them as a blueprint - which incidentally is what Bauplan means in German.
A blueprint for your first Lakehouse
1. Think in terms of end-to-end flows
Your first lakehouse should give you a straight path from raw data to something usable:
- Land files in object storage.
- Import them into a table format that handles schema and time travel.
- Apply transformations.
- Make results queryable.
- Expose them for dashboards, notebooks and downstream services.
That entire cycle should live in a single workflow as much as possible, rather than being fragmented across scripts and services. Otherwise you’ll spend months writing ingestion jobs, managing catalogs, wiring Spark and Kubernetes clusters, and chasing logs, only to end up with a brittle system that’s more complex than the use case it was supposed to solve.
The goal isn’t to assemble every tool under the sun, it’s to have one coherent flow you can run, test, and repeat.
2. Don’t use Spark unless you really have to
Spark started in 2009 when the newly announced AWS EC2 had 7GB of memory and 8 vCPU, which is less than a lambda now. Today, most workloads can fit comfortably on a single node.
If you don’t genuinely need distributed execution, you’re usually better off with simpler single-node systems. SQL engines like DuckDB, or Python libraries like Pandas, Polars, and Ibis, can handle a surprising share of pipelines without clusters, JVMs, or Spark-specific expertise.
Spark still has its place, but the bar for when you actually need it is higher than ever. If your data fits comfortably on today’s hardware (and for most teams, it does), our advice is to keep it simple.
3. Python, Python, Python!
Your data stack is no longer just for BI dashboards. In 2025, even small teams are expected to support AI features (RAG, embeddings, personalization) alongside analytics. Those workloads are practically API-driven applications, which means SQL alone isn’t enough.
Today, Python is now the most used language, and historically the go-to language of Data Science and AI, so make sure you treat as a first-class citizen in your lakehouse.
Of course, you want to keep using SQL for aggregations, joins and analytics because they are better expressed in SQL, the ecosystem around SQL is vast, and more people in your company will be comfortable writing SQL than Python (although LLMs and code agents are starting to blur that line).
Modern libraries like DuckDB and Polars make it possible to have a good Python AND SQL experience for everybody with shared columnar backbone in the Lakehouse.

4. Keep things reproducible and testable
Small teams need to do a lot with little. They need to experiment and iterate quickly, with the confidence that they can debug, test, and roll back instantly if something breaks in production.
That’s why we baked a git-style workflows right at the heart of our platform. All table formats like Iceberg give you the primitives: transactions, snapshots, and time travel.
Git-like workflows are a higher leve abstractions and it’s honestly hard to say what to do without pushing you our product, because it’s a lot of work to get it right. If we were to phrase it in terms of capabilities, these are the things that in our opinion make a huge difference in working with data:
- Data branches — isolated environments where developers can work safely. Git-like data branches should ideally span multiple tables, so you can test end-to-end changes without touching production.
- Transactional pipelines — every pipeline run should behave like a transaction: either all its outputs are committed together, or none are.
- Atomic merges — merging a branch into main publishes all changes in one unit. The system state is always consistent; there are no partial updates.
- Rollbacks — every run leaves behind a commit you can instantly roll back to and a built-in audit trail. Debugging and disaster recovery become a checkout command, not a week of archaeology.
5. Stay open and shift left to save money
The lakehouse is valuable because it avoids lock-in, so don’t give that away. As your needs grow, you’ll want the freedom to plug in the right tools for the job: Spark for massive batch jobs, DuckDB for “reasonable scale” queries, Polars for transformations, warehouses for serving dashboards, and so on.
A warehouse will often be part of your architecture if you need fast BI dashboards, and that’s fine. Just don’t treat the warehouse as the center of gravity for the stack.
Warehouses are not an flexible or cost-effective place to run heavy transformations, so shift those workloads left, into the lakehouse layer, to contain costs. Most importantly, if your data only exists inside a warehouse’s proprietary storage, you’re locked in and moving out later will be painful.
A solid first lakehouse keeps your data in cloud Object Storage you control as Iceberg tables, and runs transformations in simple Python or SQL with tools like Polars or DuckDB (no Spark). Warehouses plug in at the end to serve curated tables for dashboards, and do what they’re best at: serving queries fast.
Conclusion
If you’ve made it this far, you’ve probably recognized yourself somewhere in the story. Postgres takes hours, queries buckle under concurrency, AI features demand fresher data than you can safely provide: time to go Lakehouse.
The lakehouse is the right destination, but how you get there matters. DIY is slow and brittle. Enterprise platforms are powerful but heavy, and better suited for Fortune 500s with platform teams and compliance departments. For lean, high-leverage engineering teams, the path lies in between: start with something whole, minimal, and reproducible.
Think of Villa Savoye, not a baroque palace. What you want from your first lakehouse is not grandeur, but livability: one coherent flow from raw files to usable tables, Python and SQL in the same runtime, Git-style safety nets, and an open core you can extend later.
That’s the blueprint we followed in building Bauplan, because we saw a hole in the market for exactly these kinds of teams. Whether or not you use our platform, the design principles hold. If you adopt them, your three-person team can ship data like a thirty-person team — fast, safe, and without getting lost in 600 rooms on the way to the bathroom.




