Trustworthy AI in the Agentic Lakehouse: from Concurrency to Governance



Read the full paper: arxiv.org/abs/2511.16402
GitHub implementation: github.com/BauplanLabs/the-agentic-lakehouse
Accepted at: AAAI 2026 Workshop on Agentic AI
AI agents are getting smarter, but enterprises still don't trust them with production data. The problem isn't intelligence—it's infrastructure.
Traditional lakehouses weren't designed for AI agents. When agents can drop tables, pollute data lakes with hallucinations, or leave pipelines in inconsistent states, the governance challenges become insurmountable. Most platforms try to solve this by adding more tools, more interfaces, and more access controls—which only makes the problem worse.
In our new paper, we argue for a different approach: solve the concurrency problem first, and governance follows naturally.
We draw inspiration from databases, where MVCC (Multi-Version Concurrency Control) enables safe concurrent access through transactions. But naive transplants don't work in distributed, multi-language lakehouses. Instead, we propose git-for-data branching, declarative Python APIs, and isolated FaaS execution—all bound together through a single unified API.
Agents can iterate safely on temporary branches, with atomic merges protecting production data. Network-isolated functions prevent malicious packages. Declarative I/O creates a narrow, SQL-like surface for authorization. When concurrency is solved correctly, governance becomes straightforward.
We demonstrate this with a working implementation of self-healing pipelines, where agents debug and fix broken workflows while production data stays protected throughout.
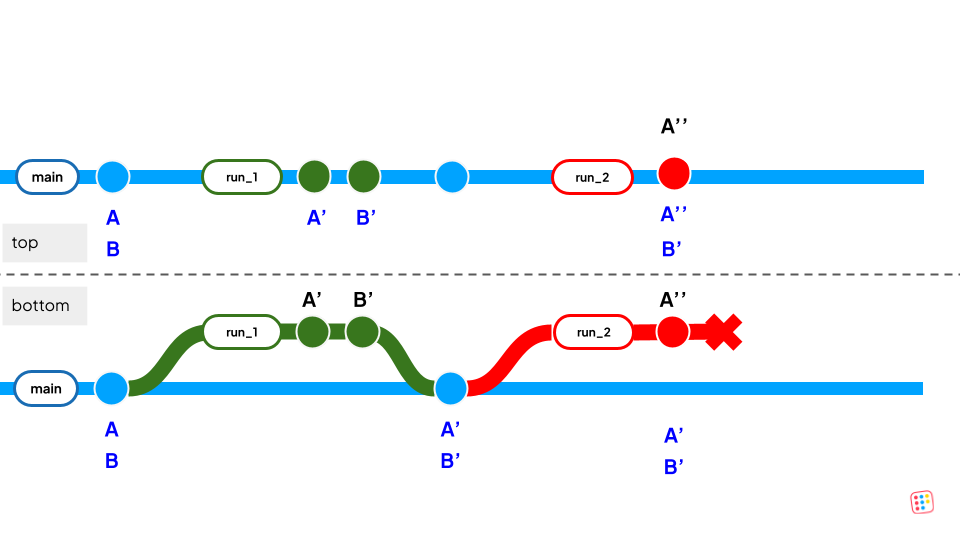
Top: without coupling temporary branches with pipeline runs, run 2 will leave in main a new version of A but an old version of B.
Bottom: Bauplan run API will guarantee atomic write of A′ andB′ on success – run 1 –, and isolation in case of failure – run 2




