Give Claude your data (on a branch)


In the last year, my day-to-day work changed pretty wildly. I used to work in many different applications and platforms, jumping from one browser tab to another, while now I am spending most of my time programming AI agents and reviewing their outcomes. Not everyone is necessarily in full agent mode, but it is a fact that Claude Code, and increasingly more Cowork, are spreading incredibly fast in every organization, radically changing the way both technical and business users work.
The main change is a shift in the center of gravity from the applications onto agents wired to the applications. The final users no longer spend the majority of their time in the platforms, but rather in Claude.
In this new way of working, giving Claude access to your company data becomes extremely valuable, because it makes your agents able to reason about your specific business and allows them to answer a wide range of needs in your organization.
A developer wants to stand up the dataset behind a new feature and backfill it. A sales rep wants to turn "what was revenue by region" into the clean, recurring table the dashboard reads from. A finance lead wants last quarter numbers recomputed in a new way and saved for next time. A platform engineer wants a broken pipeline fixed, a schema evolved, a legacy job migrated, a ticket closed.
One consequence of AI adoption is that the set of people who need genuine access to your most valuable data expands far beyond the specialists. Work that used to require a data engineer is now within reach of anyone who can describe what they want.
In fact, if you are in a data or analytics org today, you have probably felt that pull. More stakeholders are waiting in your queue with a growing sense that the entire promise of these tools is to let people finally serve themselves, through their agents, without waiting on you.
Which brings up the central question of this post: how do you let an agent operate on sensitive, valuable, production data safely, and for everyone who now wants to, at once?
Let’s just give Claude access to our data
Well, not so fast. We have at least two problems.
One, production data is shared truth for a lot of applications and stakeholders. One bad write corrupts it for everyone downstream, and unlike a bad line of code, there is often no clean undo. Allowing AI agents to manipulate production data without guardrails sounds like a dangerous idea.
Two, new data assets should be produced with care. Ask ten people for "revenue by region" and their agents might write ten queries making silent choices: revenue booked or recognized, net of refunds or gross, region by billing address or by sales territory, the quarter measured on order date or ship date, and so on. Ten reasonable definitions, but ten different numbers answering ten subtly different questions that all sound identical.
Now each of those answers gets saved as a table: regional_revenue, revenue_by_region_final, rev_reg_2026_v2, each materialized by a different agent for a different stakeholder. Other agents then discover those tables and build on them, making it very hard to keep track of what is created over time.
That is table sprawl, and it is often how a figure lands on a dashboard and no one can say which of forty near-identical tables produced it, or which definition that table used, so no one can say whether it is right.
So you are caught between two instincts that are both right. Enable the AI, because the leverage is real. Protect the data, because you are accountable when it breaks or becomes unmanageable.
.png)
Software solved this fifteen years ago
A modern software team ships hundreds of changes a day. Its contributors vary wildly in skill and trust: from staff engineers to straight-out-of-school interns, and now a growing flock of coding agents.
By the logic above this should be sheer chaos, but it is not because we have git and CI/CD. You work on a branch, an isolated copy where you can do anything without affecting anyone else; your changes get reviewed by other engineers and then go through automated tests and then, only when they pass, they reach production; and if something slips through, you can always roll back.
This model allowed software teams to grow to thousands of contributors, and then start handing the keyboard to machines. On the other hand, data never developed a similar model and mostly stayed in the world before version control: one shared production state, a handful of trusted people allowed to touch it, and everyone else waiting in their queue.
The obvious fix would be to bring branches into data, but for years this was easier said than done. While code is text that occupies only a few megabytes, data is typically expressed in GB and TB (at least in most everyday enterprise tasks). Nobody is going to clone a three-terabyte table every time someone wants to just try something. Instead, data teams made do with slow, expensive, perpetually stale staging environments.
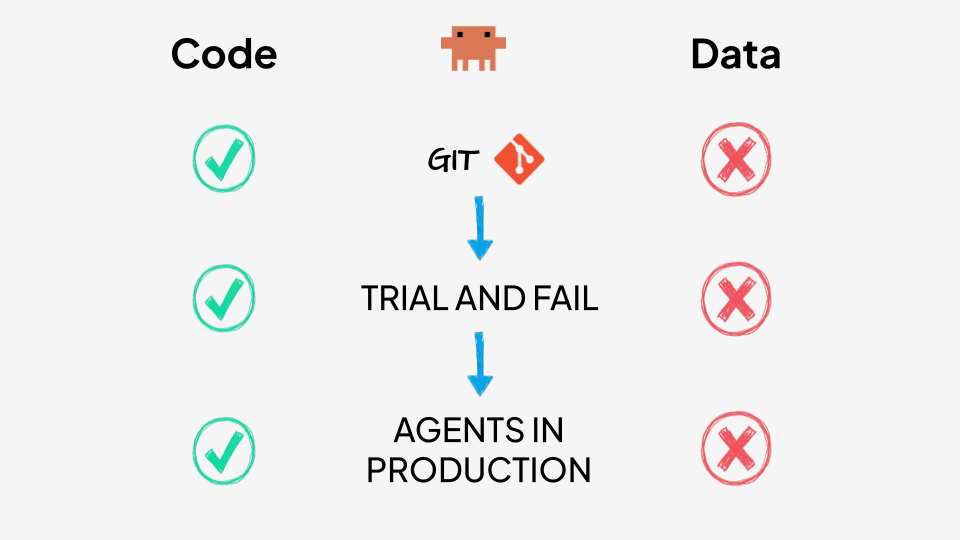
Introducing Git-for-data
Luckily enough, things have changed. Thanks to the introduction of modern open table formats, like Apache Iceberg, you can now store a table as a pile of immutable files plus a thin layer of metadata that records which files make up the current version of the table.
Because it is the metadata that defines the table, you can make a new version of that table by using the metadata instead of the data itself. This zero-copy operation takes milliseconds and costs almost nothing, providing an effective primitive that can then be used to build a full-fledged version control system over your data.
The concept of Git-for-data takes this primitive and lifts it to the whole lakehouse. Rather than versioning one table at a time, it versions all of them together and maps the mental model we apply to code straight onto your data:
- A commit is the immutable record of the state of every table at a point in time.
- A branch creates an instant, isolated copy of your entire data lake where your AI agents can now read, write, and delete with zero effect in production.
- A merge is a single atomic operation to publish the changes from a branch into production and make the tables in a branch the version everyone else sees.
- A rollback is a revert operation over the tables that have been merged. Every version of the data is kept, so reverting the whole lakehouse to yesterday, or to thirty seconds ago, is a single command.
Users can finally self-serve using Claude for complex end-to-end workflows: import this new source, rebuild a pipeline, retrain those models with the new data and publish a new dashboard. With a Git-for-data system their agents can run at full power in their own data branch and production sees nothing until the whole workflow succeeds and a merge publishes it.
The merge gate is also a very powerful way to allow self-service while avoiding table sprawl. With a branching model, any exploration happens on branches, which are isolated and disposable, so the divergent tables never reach the shared environment unless we want it to. The only tables that land in main are the ones that came through a merge, and the merge is where a CI/CD process governs what gets in: automated checks confirm the data meets its quality expectations and the schema is right, and a person approves the version that should be canonical.

Agents want Git-for-data
Revenue by region, one more time. This time let’s see how one of our customers, Moffin, does it using Claude Cowork and Claude Code.
Picture the same question from before, "revenue by region this quarter versus the last one," typed into Claude by a sales rep who has never written SQL and never will. Two things can happen (and both are safe).
- If a reviewed table already answers the question, Claude just answers. And it is a reliable number that comes from the one table that made it through review.
- If no such table exists yet, Claude files a ticket in a ticketing system like Linear and hands the real work to an implementation agent which does what one of the engineers would have done: it creates a data branch, it pulls in the data it needs, builds a pipeline, runs your quality checks, confirms the results match the answer the rep is looking for, and opens a pull request for the data engineering team.
One of the engineers reviews the tables created by this agent, and merges when it is green. The answer is now permanent, tested, and canonical, and the next person who asks gets it straight from that table, identical.
.png)
Now look at what just happened from the point of view of the data platform team. The rep never joined the queue to request the data asset and the data platform team never lost the power to decide what becomes true. Nothing either agent did could touch production until a human approved the merge. And a throwaway Tuesday-afternoon question turned into a governed, reusable asset instead of a screenshot that contradicts next week's screenshot.
Data engineering is software engineering
You often hear that data engineering is not software engineering. In software the spec lives in the code, in data it lives in the data. Software tests are deterministic, data tests are statistical. Software fails loud and rolls back, data fails silent and the damage is permanent.

This accurately describes the past, but the future is different.
Start with failure. Data failures were silent because bad data reached production with nothing standing between the mistake and the people downstream. They were permanent because there was no earlier state to return to.
It doesn’t have to be this way. Put the pipeline on a branch and run the quality checks before anything is published, so a bad result surfaces on the branch and blocks the merge. Keep every version and a bad publish is undone in one command. The most frightening property of data turns out to be a property of a workflow that had no branch, no merge, and no rollback.
The same goes for the rest of the argument. Data does carry an empirical element that code does not, since the world changes and your sources drift, so some of the spec will always live in the data. But when the data is reproducible from the code that made it, that spec is versioned, reviewed, and re-runnable like everything else.
.png)
Agents are software-native: they were built in the world of code, branches, tests, pull requests, and reverts. The way to have agents accessing the data at scale converges on the workflow that software has run for fifteen years: branch, write, validate, merge.
In the old world, the number of people who could safely touch your production data was capped by trust, so what your company could do with its data was capped by the size of your data team.
When data works truly like software, contribution is governed by review instead of by trust: anyone, and any agent, can do the work on a branch, and you decide at the merge what becomes real.




