
Built for production data work, without lock-in or migration
Bauplan is a data lakehouse designed to run real production workloads while staying simple, interoperable, and controllable.
Bauplan is a data lakehouse designed to run real production workloads while staying simple, interoperable, and controllable.
Bauplan is a data lakehouse built on open formats. Data is stored in object storage and managed using Apache Iceberg, giving you transactional guarantees, schema evolution, and time travel without tying you to a single engine or vendor.
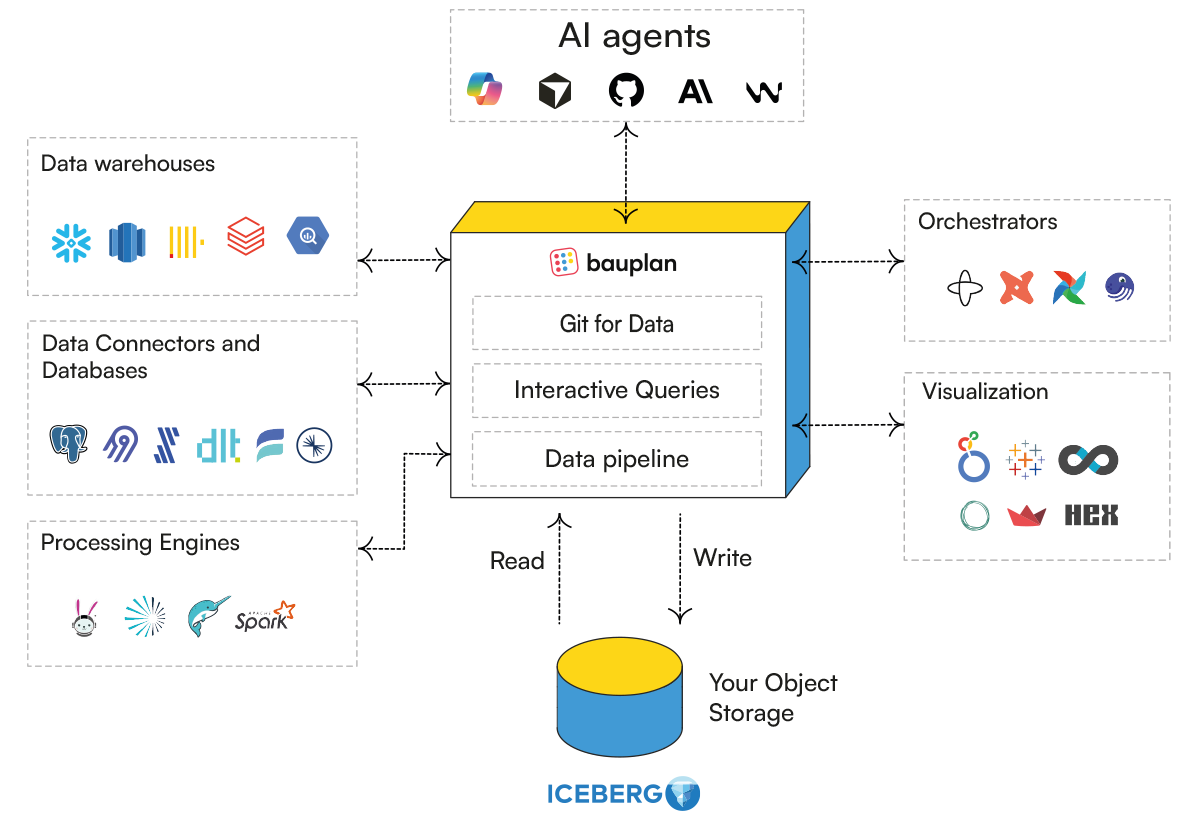
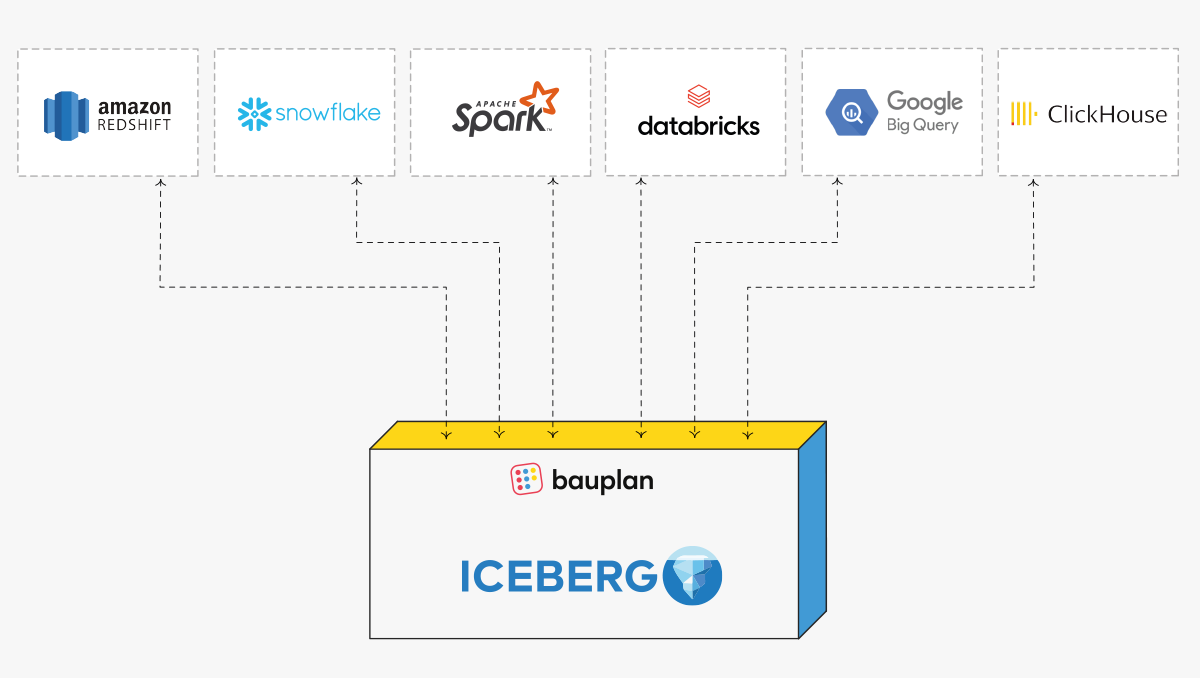
Bauplan runs alongside the stack you already have. The warehouses, query engines, orchestrators, and visualization tools you use today-Snowflake, BigQuery, Databricks, and all others, read the same Iceberg tables Bauplan writes. No migration. No data copy.
You can run Python, SQL, and mixed workloads on the same tables. Curated data stays portable and accessible across your stack.

Bauplan uses a function-as-a-service execution model for data pipelines. You write pure Python. Bauplan handles execution, isolation, and scaling. There are no clusters to manage, no long-running infrastructure, and no hidden runtime state. Each run is deterministic, isolated, and reproducible.
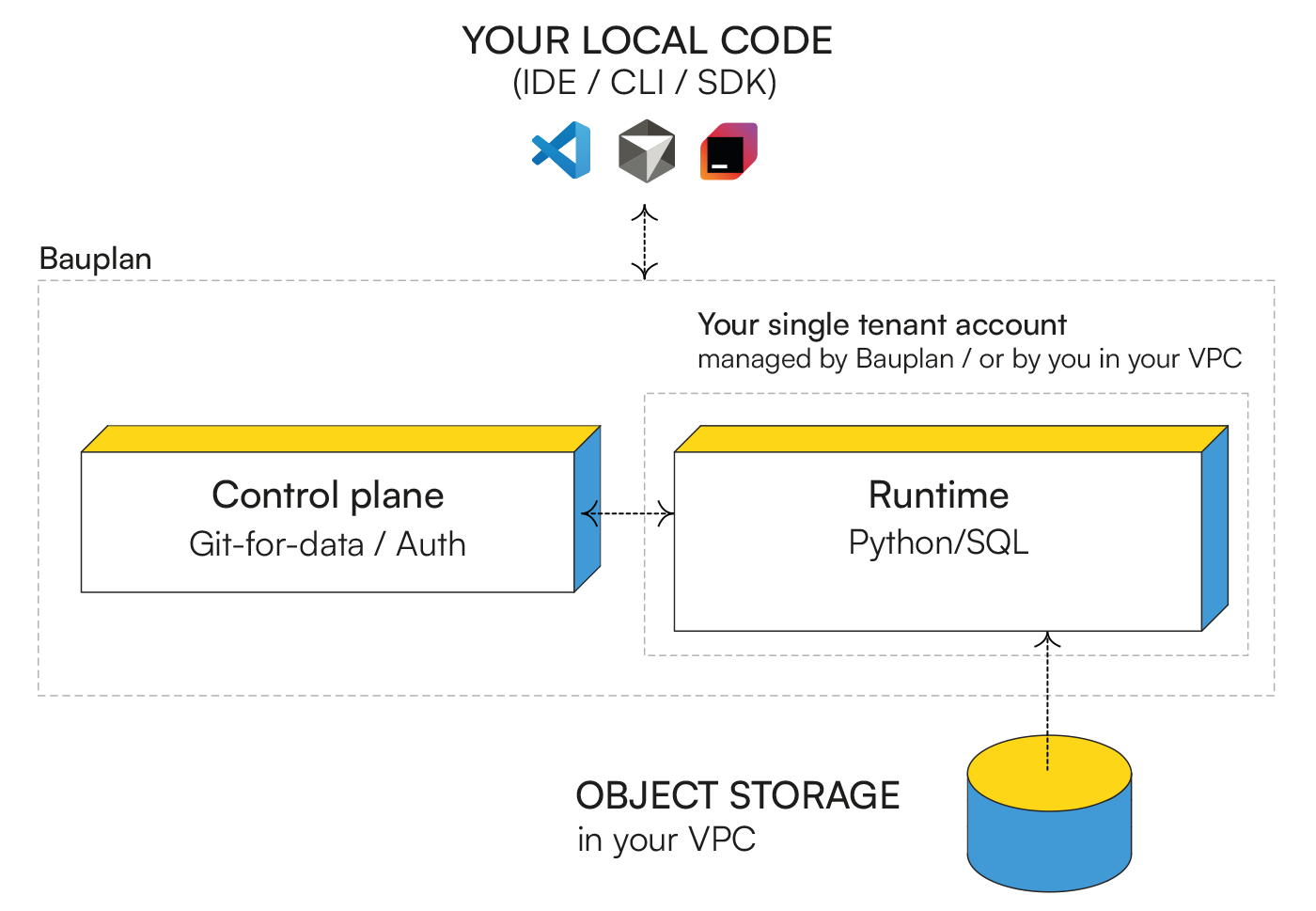
Bauplan runs production-grade workloads without the operational overhead of traditional platforms. Deploy in single-tenant environments, use PrivateLink for network isolation, or bring your own cloud with BYOC. Your data stays in your object storage at all times. There is no copying or centralizing data into a proprietary system.

Bauplan is SOC 2 Type II compliant and includes built-in isolation, access controls, and auditability suitable for regulated environments.
Run pipelines in Bauplan, then expose curated Iceberg tables to warehouses, lakehouses, and SQL engines. Connect tables directly to BI tools. Query data through Bauplan itself. Or use the Python SDK to work from your preferred notebook environment.You control how data is consumed and where computation happens.

Great! Bauplan is built to be fully interoperable. All the tables produced with Bauplan are persisted as Iceberg tables in your S3, making them accessible to any engine and catalog that supports Iceberg. Our clients use Bauplan together with Databricks, Snowflake, Trino, AWS Athena and AWS Glue, Kafka, Sagemaker, etc.
Bauplan consolidates pipeline execution and data versioning into one workflow: branch, run, validate, merge. You can keep S3 and your orchestrator; you remove a lot of cluster complexity and glue. For example, an Airflow DAG that spins up an EMR cluster, submits Spark steps, then runs an AWS Glue crawler to refresh the Glue Data Catalog before triggering downstream jobs becomes: Airflow triggers a Bauplan run on an isolated branch that writes Iceberg tables directly to S3.
Your data stays in your own S3 bucket at all times. Bauplan processes it securely using either Private Link (connecting your S3 to your dedicated single-tenant environment) or entirely within your own VPC using Bring Your Own Cloud (BYOC).
No. Bauplan is just Python (and SQL for queries). That why your AI assistant can immediately write Bauplan code with no problem.
Bauplan allows you to use git abstractions like branches, commits and merges to work with your data. You can create data branches for your data lake to isolate data changes safely and enable experimentation without affecting production, and use commits to time-travel to previous versions of your data, code and environments in one line of code. All this, while ensuring transactional consistency and integrity across branches, updates, merges, and queries. Learn more.