Agents Just Want To Have... Branches


TL;DR: a Columbia University paper argues that branching databases are both crucial and far from optimal as coding agents become the primary users of OLTP systems. Under the same assumptions, we perform branching comparisons across lakehouses, highlighting the need for purpose-built systems such as Bauplan, which is ~100x faster than alternatives.
Last month, Columbia researchers presented a new paper at ACM SAO. “BranchBench” is a novel benchmark on OLTP databases for branching-first workloads, such as data cleaning and Monte Carlo simulations. In the era of coding agents and agentic data systems, how easily, quickly and cheaply can you branch your data, perform destructive operations (e.g. replace tables), query the results and decide whether to merge or discard the work?
We have teamed up with Elaine and Sam from Columbia and repurposed many ideas for the OLAP world: if we could branch a lakehouse, data engineering would be done by coding agents, safely, concurrently, at scale. Can we?
Why branch in the first place?
As we highlighted in our AI Council talk, the primary users of data systems are now agents. In BranchBench’s own words:
"Agents are changing database workloads from operations over one evolving database state into agentic speculation (...). These workloads combine branch creation, connection isolated schema and data mutations, branch-local evaluation, cross-branch comparison, and pruning over wide or deep exploration trees."
While in OLTP writes are point-wise operations over individual rows, in OLAP changes take the shape of a data pipeline, a series of transformations modifying possibly millions of rows at a time. Production use cases from Bauplan users highlight the crucial role of branches also for agentic OLAP workflows.
Customers use a Ralph-style loop to migrate pipelines into Bauplan: agents try some code, verify against gold tables, then try again - branches allow iterations on production data, safely, while agents can build on top of each other by branching off previous branches.
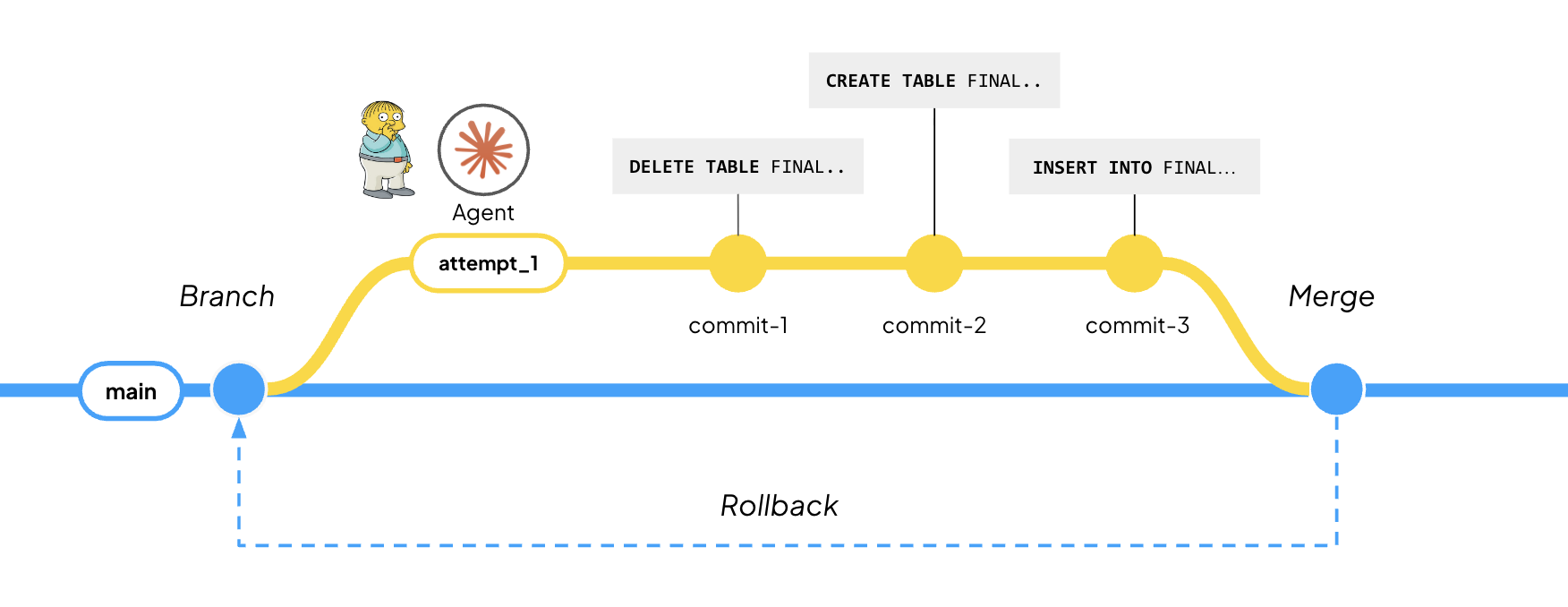
Data ingestion is another typical branching workload: the write-audit-publish pattern prescribes that new data gets appended to a lakehouse table in a branch and only published if it passes quality checks, therefore avoiding polluting production with low quality data.
Aside from infrastructure metrics (e.g. how fast can we create a branch?), the ergonomics of the flow then play an important role: can you arbitrarily branch off a branch? Are the branching semantics complete enough to support the full data lifecycle? Let’s evaluate the state of major OLAP platforms along these two dimensions, starting from branching operations and leaving mutations and evaluation (in the jargon of BranchBench) for a second deep dive.
The state of lakehouse branching
Agent-friendly APIs
The original motivation for OLAP branching was porting the CI/CD flow to data warehouse changes. Unsurprisingly, both Snowflake and Databricks support “shallow cloning”, where a database (Snowflake) or a table (Databricks) can be cloned without incurring the full cost of data copy. Their respective commands are:
-- create branch B from source database S
CREATE DATABASE B CLONE S;and
-- create branch B from source schema S
CREATE SCHEMA B;
CREATE TABLE B.t SHALLOW CLONE S.t; -- for each table t in SThe equivalent in Bauplan is a branching-native API, available both through a CLI command and a typed SDK method:
bauplan checkout -b jacopo.my_branch
client = bauplan.Client()
my_branch : Branch = client.create_branch("jacopo.my_branch", from_ref="main")Similar to Bauplan, Snowflake cloning semantics are fairly liberal, so you can clone from a clone and iterate; instead, Databricks explicitly prevents nested shallow clones. Note also that Databricks cloning works per table, not per database, which introduces complexity for the client when making sure all cloned tables refer to the exact same time snapshot for the full database.
Bauplan is however the only system that exposes the lineage necessary to perform a clean merge or point-in-time operations. As a result, while “query at timestamp” is a first-class citizen for every platform, outside of Bauplan there is no programmatic way to replicate arbitrary complex flows, or, at least, nothing close to the readability, type-safety and token efficiency of purpose-built APIs.
import bauplan
client = bauplan.Client()
# Branch off main to create two tables
first_branch : Branch = client.create_branch("jacopo.my_branch", from_ref="main")
client.create_table("table_1", "s3://my_bucket/table_1/*.parquet", branch=first_branch)
client.create_table("table_2", "s3://my_bucket/table_2/*.parquet", branch=first_branch)
# Time travel: get the commit after table_1 was added, before table_2
commits = list(client.get_commits(first_branch))
after_table_1 = commits[1]
assert client.has_table("table_1", after_table_1.ref) and not client.has_table("table_2", after_table_1.ref)
# Branch from there and add a third table
second_branch: Branch = client.create_branch("jacopo.my_other_branch", from_ref=after_table_1.ref)
client.create_table("table_3", "s3://my_bucket/table_3/*.parquet", branch=second_branch)
# Merge back to main
client.merge_branch(source_ref=second_branch, into_branch="main")
The following table is a summary of the API maturity for branching on the three platforms:
Benchmarking
Inspired by the BranchBench setup, we run initial benchmarks over the three OLAP systems in four total configurations (code is available here) to get a sense of how today’s branching abstractions can support fast, concurrent agentic iterations over the lakehouse. We compare four setups:
- a full Bauplan lakehouse: branching all the public datasets in the sandbox, including the TPCH variants under the relevant namespaces;
- Snowflake default TPCH SF 1 setup;
- Snowflake Iceberg TPCH SF 1 database, obtained by creating Iceberg tables from the default ones;
- Databricks TPCH SF 1 database, obtained by first creating the relevant Parquet files with the DuckDB utility, then uploading them as tables.
Our workloads are organized into experiments, where each experiment consists of creating or deleting N = 10 data branches for each backend and each execution mode (parallel, serial, and serial with nested branching). We run all tests from an EC2 in the same region as the target lakehouse to minimize network latency, and we time the creation and the deletion operations separately. The final numbers exclude connection setup, warmup, and name generation from the measured interval: ignoring the setup and compute model across providers simplifies the interpretation of the results as they relate to branching capabilities, which is the focus of this first deep dive.
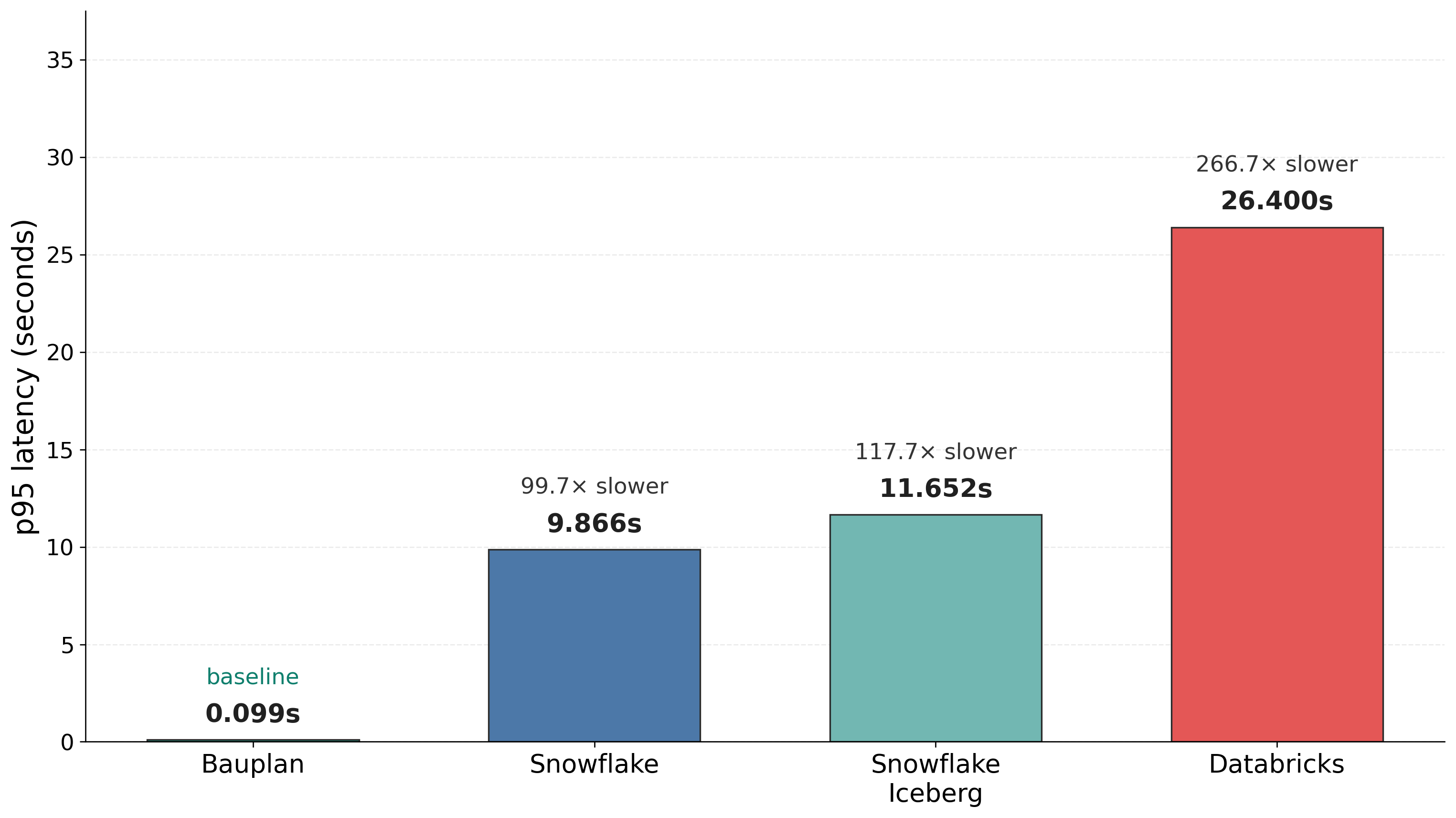
While we refer the reader to the repository for generating the full set of metrics, the table shows the time needed to perform the atomic branch creation operation in the simplest scenario, the serial one (similar speedups hold for the other two). Note that, for CI/CD use cases, a 10-second cloning delay is not ideal, but probably acceptable; for agents exploring many branches in loops the fixed cost quickly becomes the dominant tax. In other words, the advantages of a purpose-built data infrastructure compound quickly at an agentic scale.
The average and p95 for the four setups differ significantly, even if Bauplan is branching way more datasets than just the TPCH. In particular, Bauplan branching is ~100x faster than Snowflake on Iceberg, and ~250x faster than Databricks shallow cloning; as mentioned, Databricks cloning works per table, which definitely doesn’t help with latency.
As a teaser, we have also included preliminary benchmarks from our new, improved catalog, scheduled for release later this year. As we are working hard for a fully agentic data platform, predictable performance in the face of massive concurrency (here shown with up to 60 workers creating branches) is an important goal.
.png)
See you, agentic cowboys
One thing we can immediately notice is that agentic end-to-end latencies will be significantly impacted by branching in all setups, except for Bauplan: our next benchmarks will allow us to quantify more precisely the magnitude of the compound slowdown of infrastructure overhead for agentic usage.
As the code is public, we invite members of the community to suggest further tests or add new providers: we focused here on platforms that are explicitly labeled as “agentic lakehouses” and that support open formats, but we are open to include a broader view of the OLAP market if there is community interest.
Stay tuned for Part 2, in which we show how we can map the original branch-mutate-prune to the OLAP world and see if the same branching vs querying trade-offs identified by BranchBench hold true in the lakehouse.




