Grit beats talent (if the infrastructure lets you fail)


If at first you don't succeed, then skydiving is probably not for you.
Steven Wright
TL;DR
We put Claude on an EC2 and pointed it at production Bauplan, armed with skills to leverage Bauplan data branches and run sandboxed transformations.
The goal: port a whole transformation layer of one of our customers from SQL to Polars, from a warehouse to the lakehouse, with zero manual intervention.
Fifteen dollars and forty minutes later, Claude was done. The pipelines pass row-level data verification and query-plan analysis. It took ~200 turns. It did it first try.
Agentic iteration is all you need
There is an emerging design pattern in AI engineering: give an agent a goal, a way to check progress, and the freedom to backtrack and let it run.
Ralph Wiggum, Cursor’s self-driving codebase, Andrej Karpathy’s autoresearch all share the same fundamental intuition: given enough attempts, modern LLMs will solve surprisingly complex tasks, provided that they can revert their own mistakes, and receive structured signals about what went wrong.
Since LLMs are remarkably good at incorporating error signals into their next attempt, each failure narrows the solution space down. If the iteration cost is low enough, wandering in the solution space, guided by fast feedback, outperforms carefully hardcoded workflows. This is the "grit beats talent" principle.
The data infrastructure gap
In software engineering, this pattern works because the tool chain cooperates: code lives in local files, Git provides branching and rollback, the compiler, plus your test suite, provide immediate and precise feedback. The agent can mess up a hundred times with not terrible consequences.
Data systems offer none of these affordances:
- State is shared. Data lives in tables in the cloud that downstream consumers read from.
- There is no branch to contain the mistakes made by the agent iterating.
- Retries are expensive: re-running a pipeline on a warehouse burns compute at dollars-per-minute rates, and the results land directly in production.
- Cloud resources, containers, environments, schemas, all require manual orchestration that sits outside the agent's reach.
In this case, it is pretty clear the limitations come from the infrastructure, not the model. Intelligence (or enough grit) is already sufficient to solve complex data tasks, but because data infrastructure do not have built-in isolation, rollback, and structured verification, an agent can touch production state exactly once.
Today's data infrastructure was built for small groups of trusted humans. Agents don’t come in small groups, they are not trusted, nor human. They operate asynchronously, at high concurrency, and they will frequently do the wrong thing. The whole point of our work at Bauplan is that we believe that the infrastructure must assume all of this, take care of it and remain safe.
What the platform must provide
The migration succeeded because the agent could fail freely. For over ~200 turns, it wrote broken pipelines, produced mismatched schemas, and generated incorrect transformations. Every one of those failures was safe. Every one of them made the next attempt better. Three properties of Bauplan made this possible.
1. Git-for-data. The entire state of the lake must be branchable, committable, revertible, and mergeable. Every write produces an atomic, immutable commit. A branch is a movable pointer to the HEAD of a commit sequence. A rollback brings tables back to their previous states and a merge reconciles differences and surfaces conflicts. In Iceberg terms, a commit is a map between table identifiers and their snapshots. A single transformation, assuming replace semantics, produces three atomic changes on a branch: delete the existing table, re-create it with the proper schema, import the data. All three succeed together or none do. The agent can now iterate because it can create branches, mess things up, throw them away, and start over.
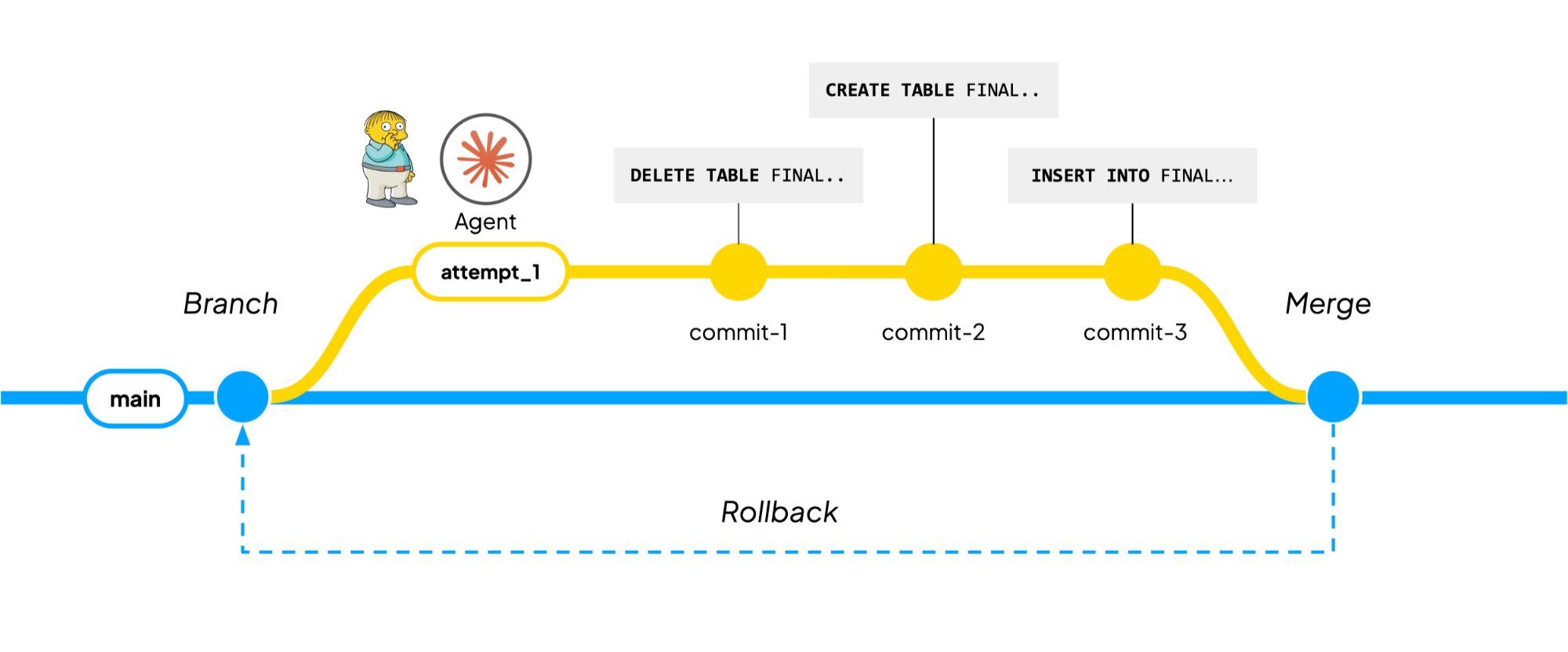
2. Everything-as-code. A self-driving codebase works because the agent can write code, build it, and run it from the same environment. Data systems are distributed cloud systems, which typically require to be operated very differently than local code. An enormous difference is made by whether the agent can run the cloud infrastructure in a way that is virtually indistinguishable from running a local script in the terminal. Bauplan exposes a very small, typed control surface so the agent can manage data branches, containers, data assets and pipelines through the same SDK and CLI exposed to the human developer.
import bauplan
# ── 1. express business logic as code dataops and devops as code ─────────────
@bauplan.model()
@bauplan.python(pip={"polars": "1.39.3"}) # ── 2. express infrastructure as code
def clean_dataset(
input_table="my_table",
columns=["col1", "col2"]
filter="datetime ='2025-12-15"
):
import polars as pl
# do something here
return clean_dataset
# ── 3. express dataops and devops as code ──────────────────────────────
client = bauplan.Client()
dev_branch = client.create_branch(branch="dev_branch", from_ref="main")
job_state = client.run(project_dir="./my_project", ref=dev_branch)
if not job_state.success:
raise Exception(f"{job_state.job_id} failed")
assert client.merge_branch(source_ref=dev_branch, into_branch="main")3. A verification policy. The agent needs structured feedback at every iteration. For a migration, this means comparing the agent's current output against the known-good source. We designed two feedback loops:
- The inner loop runs after each attempt. The agent queries the tables on its working branch and compares them row-by-row against the tables in the warehouse. This is how the agent plays “hot and cold”: if the tables differ, the agent goes immediately back to the drawing board.
- The outer loop adds a deeper check. Given that both the source and the target transformations are in a “declarative” language (SQL and Polars), it is possible to extract the plan that the underlying engine wishes to execute and ask an LLM properly prompted to verify their compatibility. This reduces the risk that the tables match for the wrong reasons.
One prompt data migration
Our setup is a dbt project deployed to a major warehouse. The project contains a Google Analytics sessionization pipeline from the production deployment of one of our customers: a venture-backed video platform that serves millions of users monthly, processing high-volume event streams across content creation, editing, and distribution workflows. The pipeline contains event ingestion, session assignment, aggregation, and export.
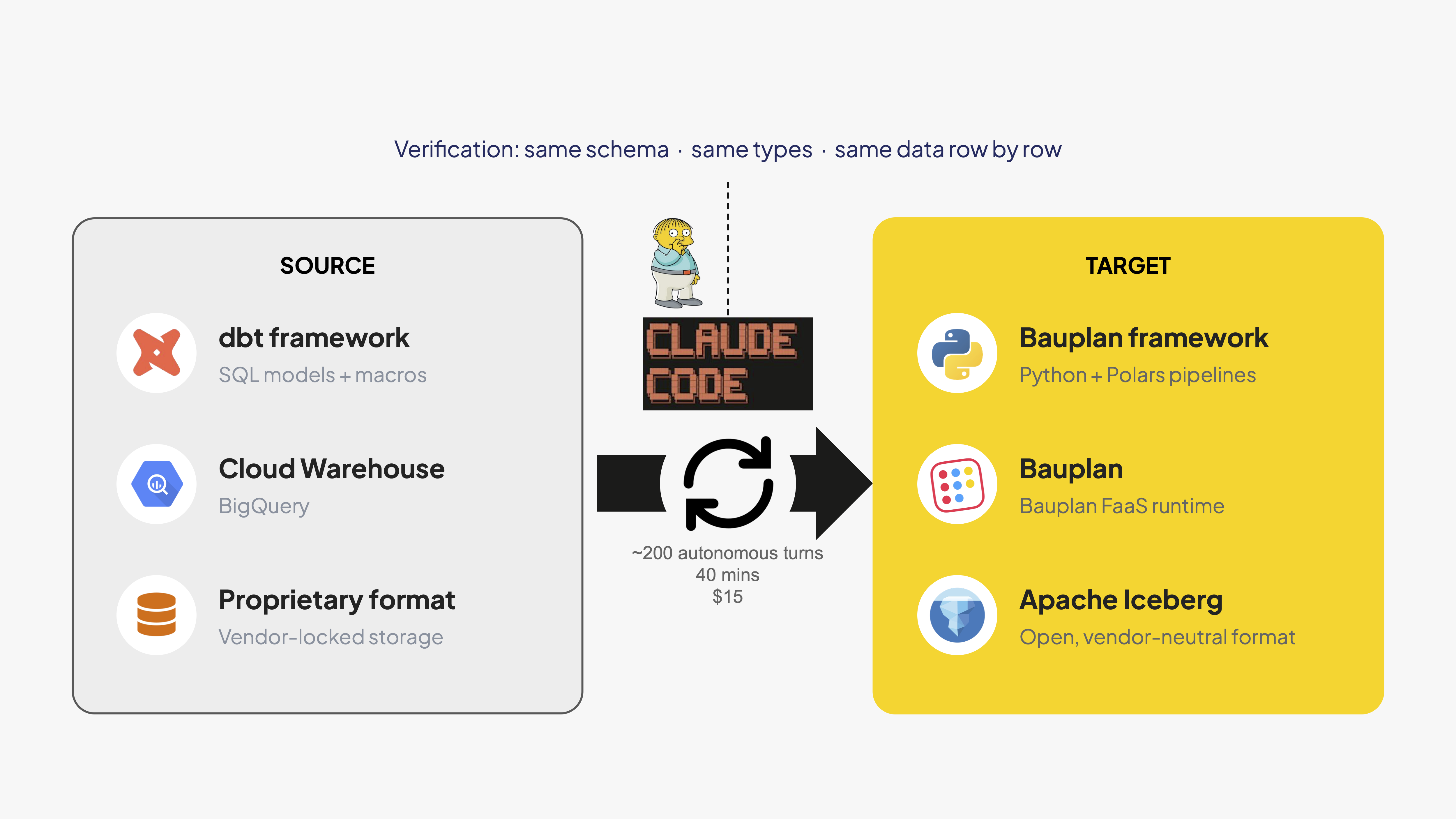
The target: a Bauplan pipeline in Python with Polars. New framework, new language, new engine. Every table produced by Bauplan must match the dbt version exactly: same schema, same types, same data row by row.
We give the agent three things:
- Bauplan SKILLs, explaining the basics of Bauplan and some general best practices. We did not include any dbt-specific instructions.
- A verification script that gives the agent read access to the existing warehouse. The agent decides what to query and how to interpret the differences against its own data branch.
- A plan-comparison script that extracts query plans from both engines and sets up a second LLM (ChatGPT 5.2) to evaluate them. The script contains no domain knowledge about the data or the transformations. All semantic reasoning is done by the models.
That's it. An EC2 with git, Bauplan production access, and warehouse read access.
We asked Claude itself to write the migration prompt (this is an excerpt):
Migrate a dbt project that turns Google Analytics raw events into session information into an equivalent
Bauplan pipeline. The Bauplan pipeline MUST use **Python with Polars only** (no DuckDB, no SQL models).
Every table produced by Bauplan must match the dbt version exactly: same schema, same types, same data row
by row.We launch Claude Code async with --dangerously-skip-permissions -yes! The agent has full access to the production lakehouse, because there is no risk anymore: the agent cannot access the internet from inside the DAGs and cannot pollute the main data branch thanks to the git-for-data system.
After approximately 200 turns of completely autonomous iteration, the job is done. The pipeline passes both the inner loop (row-level comparison) and the outer loop (query-plan analysis). It took 40 minutes, $15 and zero manual intervention.

What the agent got wrong
The migration worked on the first run, which is truly remarkable. It is also instructive to look at where the agent was struggling, because the failure modes point directly at the design space for agentic data platforms.
The agent did not immediately figure out that verification should start small. In the early iterations, it ran full table comparisons when comparing the first hundred rows would have been enough to detect a mismatch. A smarter verification harness would try to fail faster: start with a sample and widen the window only as the agent gets closer.
More interestingly, the agent did not discover that a DAG can be decomposed into sub-DAGs for incremental verification and rebuilt the entire pipeline from scratch on every attempt.
Because a DAG flow only in one direction, the best way to verify would be to branch downstream of every table that passes verification, and run only the child transformations. This is a capability that the platform supports already today, but the agent simply did not discover it on its own.
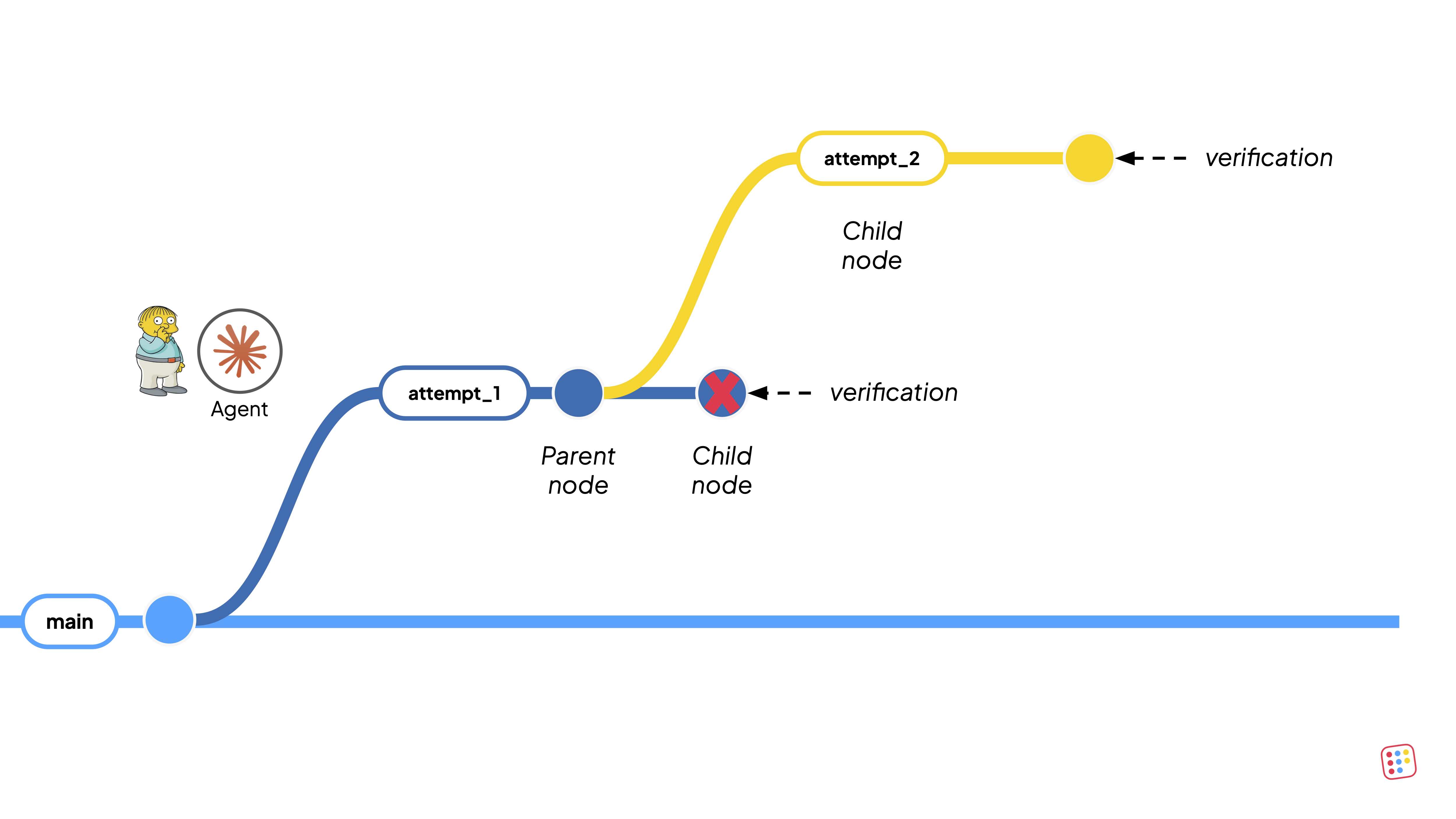
Both of these are optimization problems, not correctness problems. The agent found the right answer. A more efficient agent, or a better set of skills, would simply find it faster. So next time we put these items in the skill.
What this means
The bottleneck for AI agents in data engineering is infrastructure. Intelligence is sufficient. Models can already write complex transformations, debug schema mismatches, and reason about query semantics. What they cannot do on most platforms is iterate safely against production data.
Migrations are a good example. They have always been among the hardest problems in data engineering: high stakes, stateful, deeply entangled with business logic, and extremely tedious. Teams put them off for years. The reason is that every attempt carries real risk, and the cost of trial and error on a production system is prohibitive.
This experiment reduced a full-stack migration to one prompt, forty minutes, and fifteen dollars. The agent tried, failed, and retried roughly two hundred times. Every failure was contained. Every retry was cheap. The result passed both data-level and logic-level verification.
The same principle applies to any data task where the hard part is safe iteration: backfills, schema changes, pipeline repairs, pipeline optimization, stack modernization. The platform primitives that made this migration possible (branch, run, verify, merge) are general enough to support all of them.




