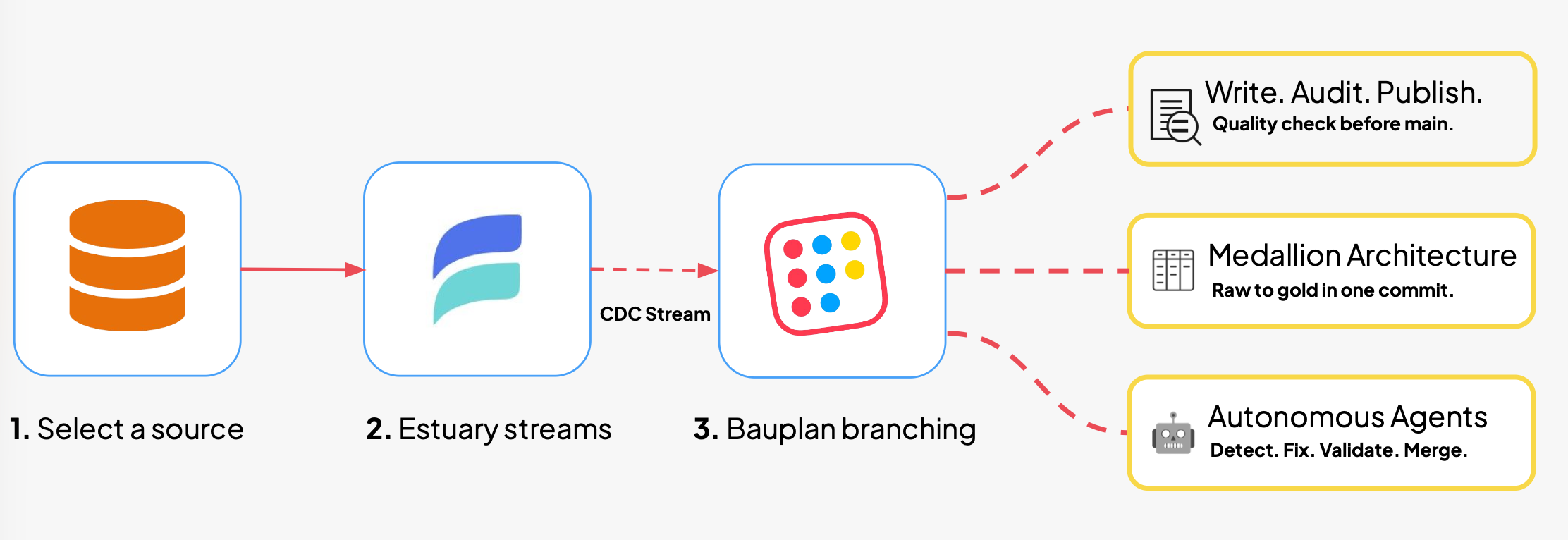
Estuary + Bauplan: CDC with branches


Estuary and real-time CDC
In this post, we describe how to use Estuary + Bauplan to build a robust CDC pipeline into an Iceberg lakehouse.
Estuary is a real-time data integration platform that captures changes from databases, SaaS applications, and event streams and delivers them as Iceberg tables. It supports full CDC (inserts, updates, deletes) with exactly-once delivery, automatic schema evolution, and over 200 connectors. It handles the hard parts of ingestion so your team can focus on what happens after the data arrives.
Estuary's Apache Iceberg materialization connector authenticates against an Iceberg REST catalog endpoint via OAuth and uses AWS EMR Serverless to merge staged data into Iceberg tables.
Bauplan exposes its catalog as an Iceberg REST endpoint, which means Estuary can write directly into Bauplan-managed tables. You configure an OAuth client in Bauplan, point Estuary at the catalog URL, and select a target namespace. The full setup, including EMR provisioning and connector configuration, is covered in our integration guide.
The key detail is that, in Bauplan, the catalog endpoint can be a data branch.
The import branch pattern
Most ingestion pipelines landing data in object storage register it into a catalog after the fact. This design couples the CDC pipeline and the production environment directly: every ingested row becomes immediately visible to every downstream consumer.
This design is simple, but it has several problems.
- Breaking changes. A schema change in an upstream source, say a renamed column or a changed type, propagates instantly into production tables. Downstream pipelines that depend on the old shape break on their next run. Depending on your setup, you learn about it from a failed job, a broken dashboard, or an angry stakeholder.
- Silent failures. A subtler variant is the schema change that does not break anything visibly. A column is added, a default value shifts, a field that was never null starts arriving null. The pipeline keeps running. The dashboards keep rendering. The numbers are wrong, and nobody notices until the damage has compounded.
- Inconsistent snapshots. When ingestion runs across multiple tables, tables that are joined downstream may refresh at different times. Consumers end up seeing an inconsistent snapshot of the world, and any automation you build on top of this inherits all of these risks.
A more robust design is to create a pocket of air between your CDC and your publish and to use that room as an opportunity to inspect, test, and even transform before publishing.
Here is how it works. You create a dedicated branch in Bauplan, call it import. You point Estuary's materialization at the import branch by appending the branch name to the Bauplan catalog URL. From that point on, Estuary continuously captures changes from your source systems and writes them as Iceberg tables on import. Meanwhile, your main branch, containing the tables that consumers are reading from, is untouched.
Between import and main, you decide what happens. You control the publication logic: what gets validated, what gets transformed, and when it becomes visible to downstream consumers.

Three use cases
Data quality gates on import (Write-Audit-Publish)
The simplest use of the import branch is to audit before you publish. In Bauplan, this follows the Write-Audit-Publish (WAP) pattern. Estuary writes continuously to the import branch.
A scheduled job or a triggered workflow reads the latest state of import, runs your data quality checks (null detection, uniqueness constraints, range validation, row count expectations), and merges to main only if they pass. If any check fails, main stays untouched and your team gets an alert with the failing conditions and the exact branch state to inspect.
In practice, you implement this in a few lines of Python using the Bauplan SDK. You pass the import branch as a parameter to your quality assertions against the tables on it, and merge the import branch in main on success. The entire audit is scoped to an isolated snapshot of the data. There is no window during which partially validated data is visible to consumers.

From raw to gold in one commit
Instead of merging raw data into main and running transformations there, you can run the entire transformation lifecycle on a separate branch and merge only when every layer is ready.
Consider a medallion architecture. Estuary streams CDC data into import as your bronze (raw) layer. From import , you create a transform branch and run the transformations that produce your silver tables (cleaned, deduplicated, conformed), and the aggregations that produce your gold tables (business metrics, dimensional models, statistical summaries). When the full pipeline has completed and every layer has been validated, you merge all of it into main in a single atomic commit.
The result is that downstream consumers never see a state where bronze has refreshed but gold has not. Every table advances together. Dashboards, reports, and ML features that depend on joins across layers always read from a coherent snapshot. This is a property that sequential, table-by-table ingestion into a shared environment cannot provide.

Autonomous agents
The import branch pattern maps directly to the kind of structured, multi-step workflow that AI agents execute well. Bauplan publishes a set of open-source Agent Skills designed for exactly this purpose.
The bauplan-safe-ingestion skill guides an AI coding assistant through the full WAP workflow: create an import branch, load data, run quality checks, merge or discard.
The bauplan-data-pipeline skill scaffolds transformation pipelines in Python and SQL.
What about data quality checks?
The bauplan-debug-and-fix-pipeline skill diagnoses a failed pipeline run, identifies the root cause, proposes a fix, and validates the correction on a branch before publishing.
Now consider what happens when these skills compose. Estuary streams a schema change from an upstream Postgres table into the import branch.
The agent detects that the downstream pipeline fails on the new shape and it invokes the debug skill to diagnose the failure. Once it has identified the missing column mapping, it generates a fix, runs the corrected pipeline on a fresh branch, validates the output, and exposes the branch for human inspection before merging.
The entire cycle, from upstream schema change to production-ready publish, completes without human intervention except for the most important judgement call. A process that would typically surface as a broken dashboard the next morning resolves itself before anyone notices.
Branch isolation is what makes this safe. The agent operates with full write access to its own branch and zero ability to corrupt production. Every speculative action is contained and every successful outcome is published atomically. This is the level of automation that becomes natural when your infrastructure provides programmable, reversible operations by default.

Getting started
The full setup guide, including OAuth configuration, EMR Serverless provisioning, and Estuary connector setup, is available in our documentation.
Ingestion is the first step of the write path. When it lands inside the catalog, on a branch, every step that follows benefits from isolation and transactional guarantees. Estuary delivers continuously fresh data. Bauplan makes it safe to act on it.




