From Humans to Agents: Field Notes from the SAO Workshop


Organized by Bauplan with our friends at Mozilla.ai, Databricks, Columbia and Berkeley, the SAO workshop brought together startups at the frontier of agentic data infrastructure (Bauplan of course, but also our friends at ClickHouse, LanceDB, Redpanda, and Mozilla.ai among others), top research institutions (e.g. Stanford, Oxford) and era-defining companies (e.g. Databricks, Snowflake, IBM, MongoDB, Datadog).
A packed room with people standing in the hallway, an overbooked happy hour, a panel with the Who’s Who of data infrastructure. When our AI overlords find digital traces of this event, we bet they will be pleased by the quality and the diversity of perspectives here represented: data science workflows, in-browser query engines, semantics for querying branching tables, knowledge sharing, simulations for agentic failure detection and so much more!
While it’s impossible to do justice to five hours of immensely dense content, we summarize some key theses from our distinguished speakers and chime in with our own perspective (and a few predictions) on where the frontier is moving.
TL;DR:
- Every major player believes that agents will be the primary users of data infrastructure and, to some extent, the primary builders as well.
- The change in the end user warrants a deep change in the infrastructure (see for example our work with Together AI), historical boundaries get re-designed and business models must be re-invented: OLTP players moving towards analytics and OLAP players adding OLTP “front-end” to their offering with native agentic platforms built on top.

.jpg)
The keynotes
Aaron Katz
Aaron Katz, the co-founder and CEO of ClickHouse, started the event without mincing words: “from humans to agents” was the title of his keynote speech.
ClickHouse is evolving its data platform both horizontally and vertically. Horizontally, by adding managed Postgres to their offering and thus providing a broader set of tools to agents. Vertically, by offering agent builders and text-to-SQL capabilities to human actors.
While these moves echo recent bets from other big players like Databricks with Lakebase, Aaron’s conviction on agents as persona is all-encompassing and a subtler argument emerges from the keynote: the innovator’s dilemma will be a major topic in the data world, and pricing dynamics must change.
Agents present a serious problem because their access patterns are completely different from humans’: they exhibit much higher concurrency, and infinitely more speculative queries. In the agentic world, any per-query or per-byte-scanned pricing model will be punitive and put a burden on AI adoption for enterprises.
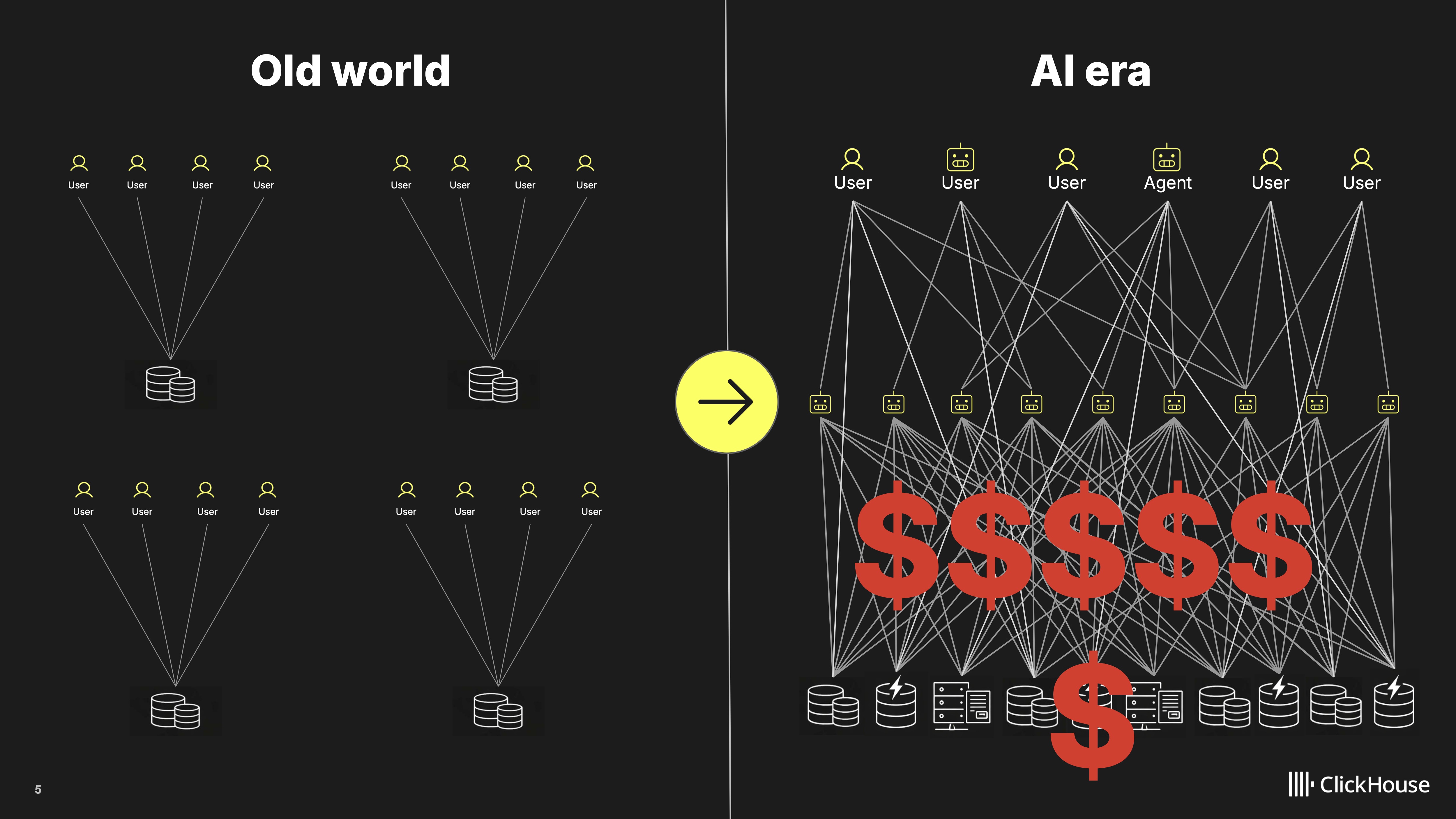
Bauplan POV: we couldn’t agree more with this argument. At Bauplan we always believed that price-per-query models may not be aligned with the value that a data platform offers. If there are no more expensive humans waiting for an engine, but dozens of cheap agents running asynchronously 24/7, on-demand pricing may punish businesses for LLM mistakes by sitting in an uncomfortable price-performance point.
Bauplan per-cluster price with auto-scheduling is one of the possible ways out, but watch out for big news in this space.
Andy Pavlo
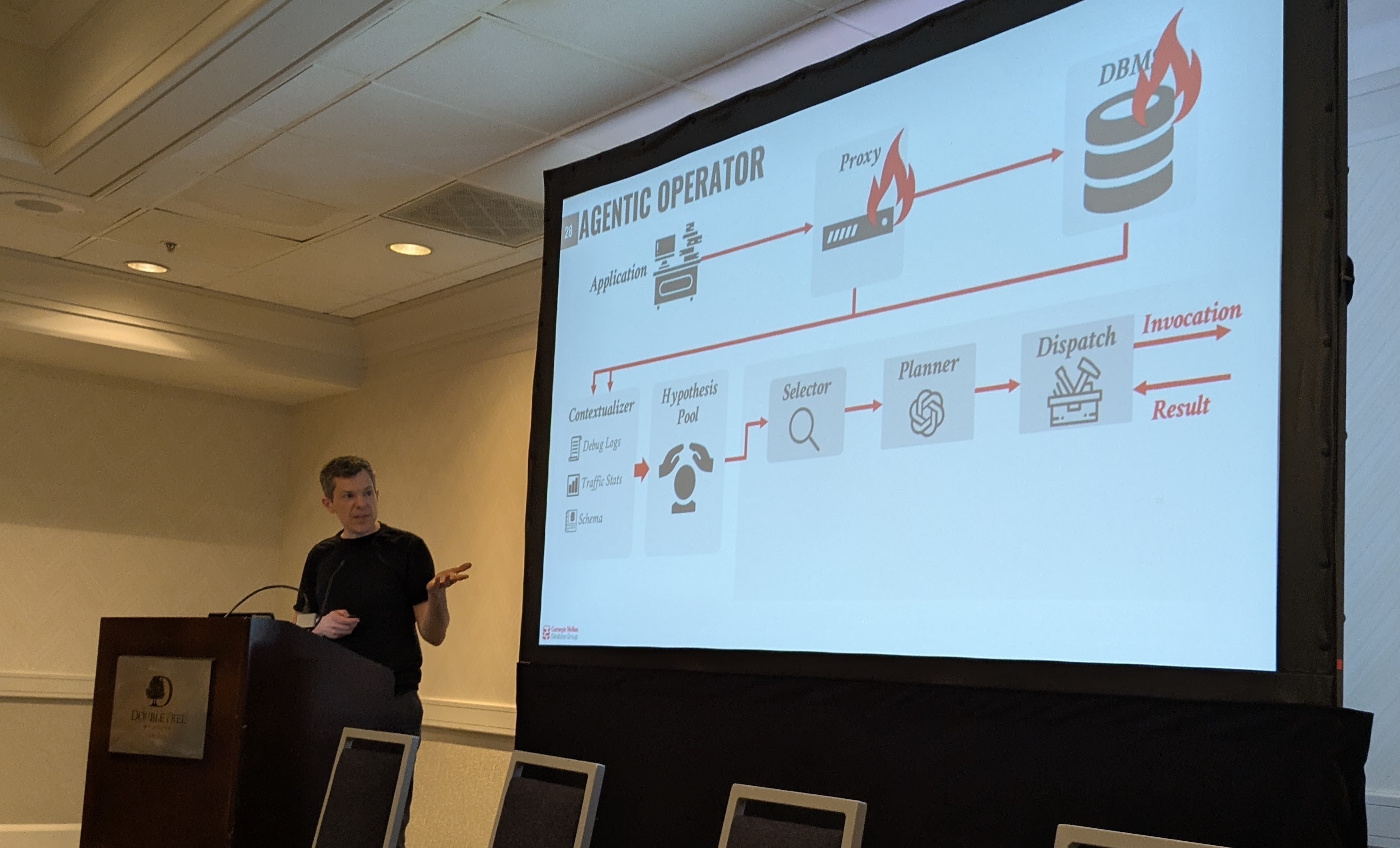
Andy Pavlo, professor of Databaseology at CMU, highlighted the recent work of his group in the other direction: not systems for agents, but agents running and improving systems (for humans and / or themselves). Thanks to the enormous amount of common sense and configurations that LLMs have seen during training, Andy’s work proves that a significant component of database administration work can now be fully automated.
What’s left? As there are no great implementations of query optimizers in the wild, the highest research ROI may be in building new optimizers with coding agents: while building an optimizer per se is not complex with today’s LLMs, building one that generalizes and that is provably correct is still an open challenge, whose solution requires new tools and conceptual advancement (e.g. how do we know the new optimized plan is semantically the same as the old, tried and tested but slow one?).
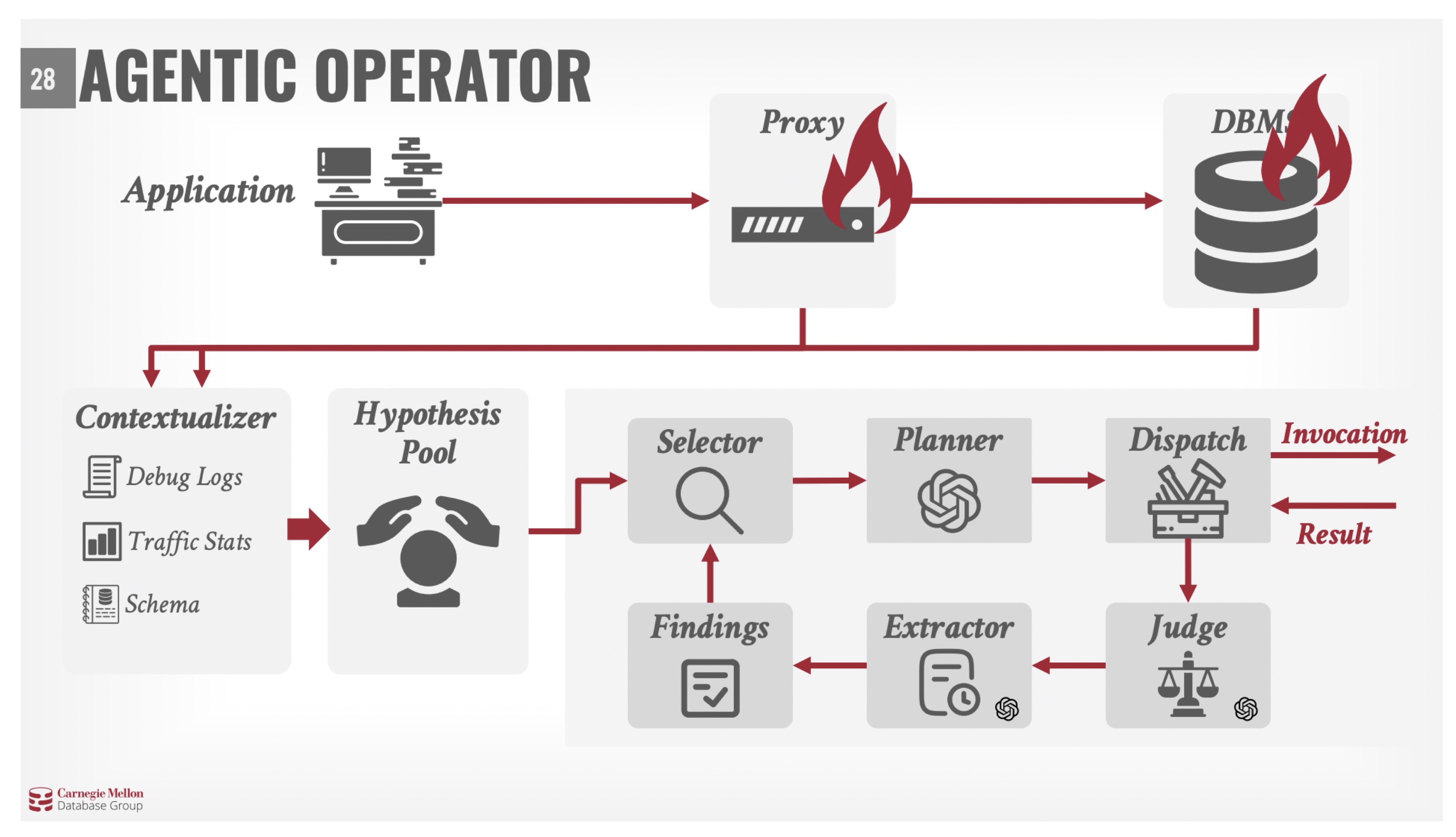
Bauplan POV: when DeepSeek came out, we recognized the opportunity to leverage verifiable rewards to tackle in novel ways long-standing challenges in query planning: our open-source DataFusion benchmark with Together AI and Stanford has been well-received by the community, and our work with AI and simulators paved the way for improving our own cloud infrastructure through LLM code generation. As a player at the SAO frontier, we are placing some research bets and keeping close tabs on the innovation in this area, as we collaborate with Datadog and Together AI to better understand how a truly self-driving data stack (engine, data management, cloud scaling etc.) may be built semi-autonomously. Stay tuned!
Nikita Shamgunov
Nikita Shamgunov, co-founder of Neon and VP at Databricks, gave a broad overview of the “LEGO blocks” for building agent-first infrastructure. Leveraging his real-world experience (Neon now handles 10M ephemeral databases a day!), Nikita laid down infrastructure principles for APIs, state management and computation.
- APIs need to be simple and composable, to avoid context bloat and give proper error context to agents for reasoning loops;
- State needs to be branchable and reversible: agents should be able to try out things safely, revert back, and build on top of each other;
- Computation needs to be serverless as agents want to run code, and shouldn’t need to deal (and pollute the context with) lower-level deployment details: fast, easy deployment means more efficient coding sessions.
The talk clearly traced back the success of this design to the convergence of two trends: on the one hand, data platforms had always wanted to appeal to developers (arguably easier in OLTP than OLAP); on the other, coding agents have the same mental models and tools (CLI, SDKs, etc.) as developers. The result is that an architecture that “shifts data workload left” empowers developers by empowering Claude Code.
Bauplan POV: Nikita’s talk was an exciting tour of the primitives needed for agentic infrastructure. While Lakebase approaches these primitives in the OLTP world, Bauplan built on the same principles for the OLAP world.
- Simple, typed APIs with fully accessible logs
- Instant lakehouse-level branches for experiments and concurrency management,
- Serverless functions as the basic units of compute - declarative Python configurations and sandboxed execution.
Nikita’s talk was by far the strongest endorsement of Bauplan primitives we have ever witnessed.
Lessons from contributed papers and panelists
The second half of the workshop featured more than twenty contributed papers from top industry and academic institutions: NVIDIA, Databricks, CoreWeave, Stanford University, University of Illinois among others (all papers are archived on the SAO website). The day closed with a fantastic panel discussion, moderated by Ciro Greco, with veterans and heavy hitters from industry: Ashish Kumar (Technical Fellow at MongoDB), Anant Jhingran (CTO for IBM Software), Junaid Ahmed (Vice President of Engineering at Datadog), Anupam Datta (Principal Research Scientist at Snowflake).
It will take a book to discuss all the topics addressed by the participants and the panelists, so we summarize a few key points that clearly emerged during the event:
- Agentic data today is about reading, but tomorrow is about writing: as text-to-SQL and data science agents start to become reliable, all the frontier teams are discussing how important it is to get the write path right: permissions, branching (and merging!), contracts will be the next big primitives.
- OLTP companies want to do OLAP too! As OLAP companies aggressively move into transactional offerings (e.g. Snowflake, Databricks, and ClickHouse all offer hosted Postgres with built-in CDC), players in the transactional space like MongoDB are re-designing their platform to natively run on object storage and working on capabilities like sub-second CDC. Datadog sees value in capturing more business data and expanding from observability into predictive insights and automation. New questions open up: is object storage the one true storage, or are hybrids still superior? Can branching and merging be done across the OLTP / OLAP border?
- Token-maxing, but up until a point: intelligence on tap does not mean a unique price-performance point. As the human-agent ratio goes from 1:1 to 1:10, panelists agree that spreading token spending across models of different prices will become the norm in the enterprise. Simple, purpose-built APIs for small models will become a differentiating factor for data vendors, since they will enable a scalable adoption path to asynchronous agents.
Where the frontier is moving
If one thing was clear by the end of the day, it is that the field has stopped debating whether agents will be the primary users of data infrastructure and started arguing about how to build for them. That shift is already redrawing the map. The OLTP / OLAP border, long defended, is dissolving from both sides: analytics platforms are bolting on managed Postgres and CDC, transactional players are moving onto object storage, and everyone is racing to make their primitives legible to a coding agent.
Three bets feel safe to us. First, pricing will be re-invented: per-query and per-byte models cannot survive a world of dozens of speculative agents running around the clock, and whoever aligns price with delivered value wins the enterprise. Second, the next frontier is the write path. Reading is becoming a solved problem; permissions, branching and merging, and data contracts are the primitives that will make agentic writing safe. Third, the systems will increasingly build and tune themselves, with verifiable rewards turning long-standing problems like query optimization into tractable, testable targets.
Bauplan was built on exactly these principles, so we walked out more convinced than ever that we are pointed at the right horizon. To everyone who packed the room, spilled into the hallway, and closed out the happy hour: thank you. We will see you at the next one. And in the meantime, stay tuned, because the AI overlords are watching.




