
Shift Left from Warehouse to Control: How Trust & Will built a Lakehouse in days

"WAP on raw Iceberg would have taken us months to build. In Bauplan it took hours. We ship changes with confidence and keep Snowflake for what it does best."
Results
- Simpler architecture and lower warehouse cost: Lakehouse, S3-based architecture reduced Snowflake load.
- Safer deployments: Every change is gated by WAP. Failed checks publish nothing. Rollbacks are instant.
- Faster iteration: Branch, test, and merge on production-like data.
- AI-ready foundation: Python-first execution unblocks agent use cases.
Painpoints at glance
- Single compute choke point: ETL and BI slowed each other down.
- Cascading breaks: Schema drift forced multi-team coordination.
- Python gap: ML and agents required exports and copies.
- Risky releases: Limited isolation, slow rollbacks, and unclear lineage.
The Challenge: Warehouse-only became a bottleneck
Trust & Will’s Snowflake + dbt stack pushed every job through one engine. ETL, tests, backfills, and BI contended for the same compute. Small schema edits rippled across models. Python and AI work sat outside production data. The team needed speed, safety, and a path to agents without breaking BI.
The Previous Stack
Everything ran inside Snowflake with the transformation expressed in dbt:
- One compute pool for pipelines, tests, and dashboards.
- Backfills that stalled users and raised cost.
- No native Python access to production tables.
- Releases that were hard to reproduce or roll back.
Introducing Bauplan: ship faster, spend less, stay flexible
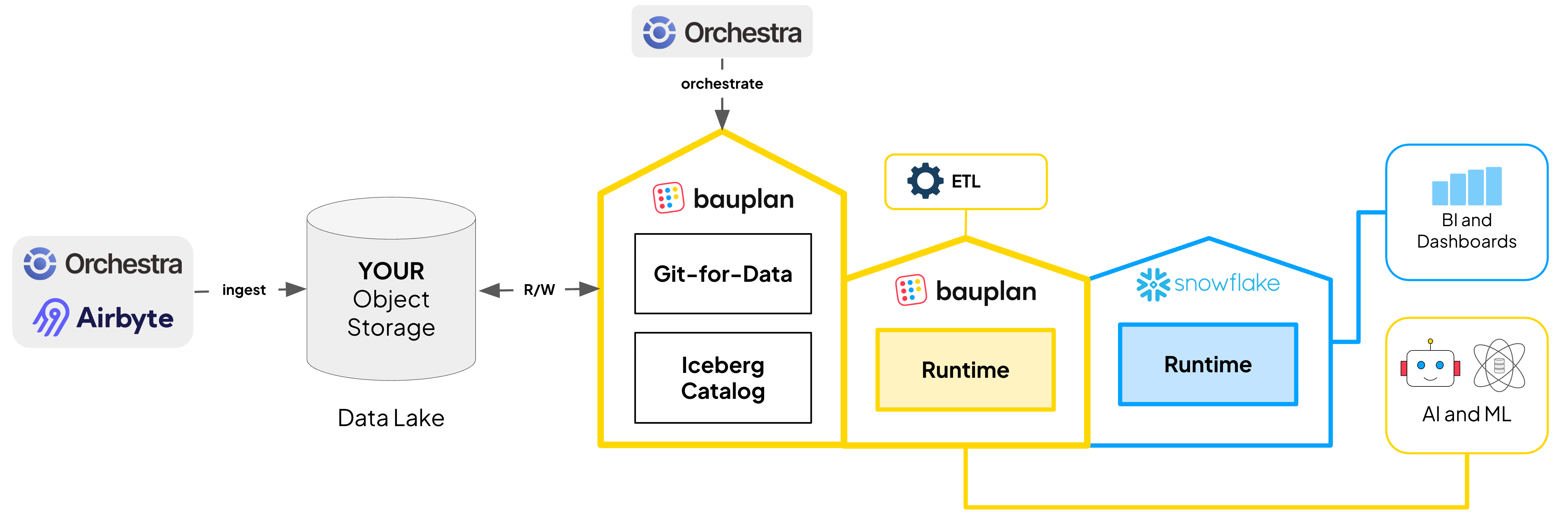
Bauplan moved Trust & Will to a Lakehouse architecture on S3 with Apache Iceberg, so transformations, tests, and quality gates run as versioned Python or SQL, close to data versions, while BI keeps working on the warehouse. The work became simpler, the outcomes steadier, and the costs lower.
- Lakehouse architecture. Leverage the power of Apache Iceberg with a few lines of Python or SQL: no extra services to wire, no platform glue, and no Spark.
- Robust automation. Declarative models and data branches create explicit contracts and atomic merges, so transformations can be automated while delivering predictable and reproducible outcomes.
- Data quality as a first-class citizen. Write–Audit–Publish runs expectations at runtime and publishes only when checks pass. Bad data never lands in the production environment.
- AI-first development cycle. Bauplan’s MCP server lets data engineers and their coding agents work safely on versioned data using their preferred AI tools.
- More freedom and lower costs. Analysts keep dbt and Snowflake. Pipelines run on S3 and Iceberg. Best tool for each job, lower warehouse spend.
Pain points solved by Bauplan ergonomics
Orchestration and lineage
Orchestration happens on Orchestra, a declarative data orchestrator. Orchestra reads Bauplan’s model contracts (inputs, outputs, expectations) and turns them into a DAG with lineage. This leads to predictable runs, fast root cause analysis, and clean promotion from dev to prod.
Snowflake as the serving layer
Gold models that must stay in Snowflake do so via external Iceberg tables that point at Bauplan-managed objects. Analytics remains unchanged while storage and transforms move to open infrastructure.
Technology stack




