
Breaking News, Steady Dashboards: How Mediaset Built a Bulletproof Medallion Architecture with Bauplan

"Before Bauplan, every major breaking news event created sudden traffic spikes that threatened to crash our dashboards. Our infrastructure couldn't handle the load, causing unpredictable outages precisely when our users were most active. With Bauplan's medallion architecture, we've eliminated the bottlenecks, the system runs efficiently even during peak traffic, and we can finally focus on our product, not our servers."
Results
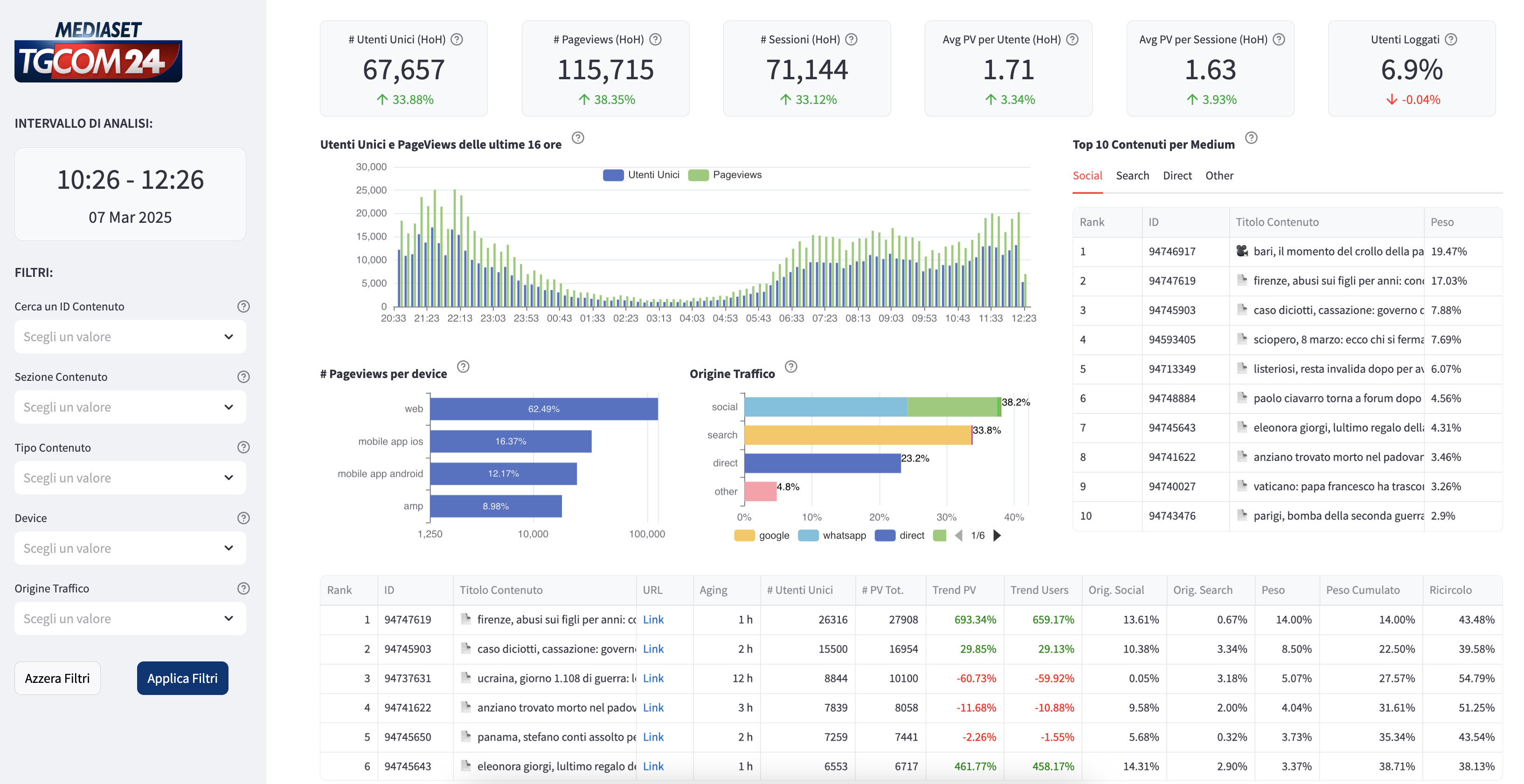
10x Performance Improvement
- Real-time insights: Breaking news metrics available within minutes, not hours.
- Dashboard load time: 5+ minutes → ~6 seconds
- Query responsiveness: Dashboards query the Gold tables with “SELECT *…” and filtering happens against the Silver layer with dynamic WHERE clauses.
- Better ergonomics: Dashboards call an API whose contract lives in the code that materializes each layer; front ends can be swapped without query changes since reads are simple range fetches.
90% Infrastructure Cost Reduction
- TGCOM24: 17GB RAM → 1.7GB RAM (10x reduction).
- Mediaset Sport: 8GB RAM → 0.8GB RAM (10x reduction).
- Total infrastructure: Order of magnitude smaller across all services.
Team Velocity & Simplicity
- No more senior engineers and Qlik specialists: Junior developers can modify and extend pipelines.
- Pure Python development: No more juggling Spark, Athena and multiple query languages
- Faster feature development: New analytics features deployed in hours, not weeks
Painpoints at glance
- Complex and fragile stack: Spark → S3 → Athena → Qlik demanded cross-domain expertise and constant coordination.
- High training overhead: Qlik’s data model and dashboard design required senior developers and external consultants.
- Slow responsiveness: Dashboards routinely exceeded two-minute load times, far beyond newsroom tolerances.
- Operational blind spots: During traffic spikes, analytics froze, leaving editors without live engagement data.
- Limited agility: Small changes to dashboards or transformations required expert intervention, slowing iteration.
The challenge: breaking news breaking your infrastructure
Mediaset, Europe’s largest free-to-air broadcaster (~€6.8 billion in annual revenue) and reaching over 65 million viewers daily, faced a serious operational challenge.
Whenever a major story broke on its flagship digital news product TGCOM24 (celebrity scandals, political announcements, breaking sports news) traffic would surge by an order of magnitude in minutes and the analytics infrastructure couldn’t respond adequately.
When dashboards stalled, editors couldn’t track live metrics like click-throughs, dwell time, or referral mix. In other words, editors were forced to make key publishing decisions without data.
The previous Stack
Mediaset’s analytics workflow relied on a multi-layer setup: Spark jobs running on AWS EMR processed data into S3, Athena provided SQL access on top and dashboards were built in Qlik. The combination required:
- A team of senior engineers familiar with distributed systems to manage the Spark jobs and data ingestion.
- A specialized Qlik consultant to maintain dashboards and models.
Even with that expertise, the system struggled under peak load. During breaking-news surges, query failures propagated across the stack, dashboards took minutes to load, and editors went blind to audience behavior.
Introducing Bauplan: from monolithic pipelines to a true medallion architecture
Mediaset’s data team wanted to adopt a medallion architecture separating pipelines into Bronze, Silver, and Gold layers to isolate compute stages, ensure data quality at each step, and optimize the final Gold layer for fast queries.
In practice, implementing that pattern across Spark jobs, Athena queries and Qlik transformations required significant engineering effort and ongoing coordination between backend and BI specialists.
Bauplan solves this problem by abstracting away all the infrastructure and providing simple abstractions for the engineering team.
How Bauplan Enabled the Medallion Model
First, Bauplan allowed the team to replace a multi-tool stack with a unified Python-first lakehouse architecture on S3.
All transformations, from raw ingestion to Gold aggregations, are now expressed as declarative Bauplan models in SQL and Python.
Each layer became a self-contained, version-controlled function:
- Bronze. Ingestion and light filtering in SQL
- Silver. Business logic and enrichment in Python
- Gold. Pre-aggregated, dashboard-ready analytics
Thanks to declarative I/O, built-in isolation, and zero-copy branching, these stages could be chained safely without additional orchestration code or data movement.
🚀 Instead of a team of senior engineers and a Qlik specialist, two junior engineers assisted by a data lead were able to implement the full medallion workflow in weeks.
Pain Points Solved by Bauplan Ergonomics
Each model executes in its own function-as-a-service container, with pinned dependencies and atomic writes.
Because all layers share the same declarative abstraction, building and maintaining a medallion architecture became straightforward and safe.
Technology stack




