Why we develop on data locally and why we should stoP
PART 1
Ciro Greco
The road to production for data workloads is bumpier than in other parts of our stack. The separation between dev and prod is not completely clear cut, as a consequence going from one to another is often an intricate process.
A lot of the work done by data scientists, ML engineers and data analysts happens in dark corners like ephemeral worksheets, notebooks and scripts on local machines. Raise your hand if you’ve ever worked in a company where there is a data platform team whose job is to take notebooks, scripts, SQL worksheets or, more broadly, prototypes and refactor them into proper pipelines in production.
Why do we do it ourselves? Why can’t we do everything directly in the production environment in the cloud? In our experience, there are well-grounded reasons and they mostly tie back to the tooling available to data engineers and data scientists.
The cloud is hard to reason about
Cloud infrastructure is complicated, the developer experience is fragmented and sometimes counterintuitive. The impression one often has is that the system is forcing us to work around it rather than with it.
For instance, there is too much infrastructure between making a change in the code and seeing its effects. Make a change in the code, re-build a container, upload the container, stop the cluster, restart the cluster, wait for the pipeline to run end-to-end against the production data. Oh no! Something went wrong at step number 89. Start over.
If this sounds painfully familiar it is because many aspects of our infrastructure climb their way up to our developer experience while writing code, making the feedback loop incomparably slower than our local machine. Consequently, most people choose to download some sample data on their machine and work there, especially when prototyping and debugging.
Another reason for the feedback loop to be slow is that sometimes data pipelines are just slow to run because they move a lot of data and do complicated transformations and that takes time.
It is not easy for data engineers to build setups where data pipelines can be sliced and diced automatically in order to make development faster.
For instance, when a DAG is changed one can think of a system that automatically runs only the nodes that matter, while caching all the parent nodes.
Additionally, certain consistency tests can be done without having to run the entire pipeline, like we would do with unit tests in traditional software: we shouldn’t need to run an 8h pipeline end to end to know that it is going to break on the node number 120 because of type inconsistency.
All these are very valuable possible improvements, but you have to build them. So let’s just do stuff on your laptop while we figure out how to do all these marvelous things.
Blame it on stack
Data stacks are complicated. The most common architecture for enterprise data platforms is the data lake. Low-cost object storage with file APIs to hold data in open file formats (e.g. Apache Parquet), paired with downstream processing layers for the different use cases (e.g. Spark clusters and data warehouses). In fact, most Fortune 500 have one. The advantage of data lakes is flexibility, which typically plays well with the complexity of enterprises. The drawback is complexity.
Since this architecture is composable, assembling the right pieces while avoiding sheer anarchy is quite demanding. An end-to-end data platform will minimally include:
● A storage layer.
● Data cataloging and metastores.
● A general runtime.
● Container management for applications.
● Possibly, a dedicated SQL runtime.
● An orchestration layer.
● A transformation layer (e.g. something like dbt).
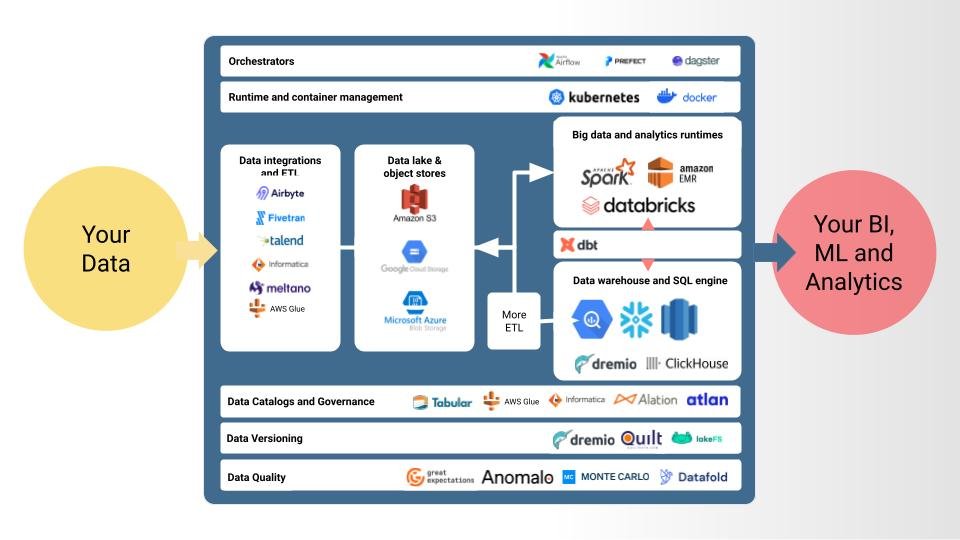
Data platforms are insanely complex engineering projects today
That’s a lot of moving pieces of infrastructure to hold everything together. Succeeding in assembling an efficient data platform depends on design, technology choices, budget constraints and mere execution. The results can vary dramatically and the impact on development practices and ergonomics can be enormous.
It might sound banal, but the principal reason why it is so hard to have efficient development practices with data in the cloud is because the stack is too complicated.
A lot of work happens on local machines essentially because developers don’t want to deal with all of the above.
Things are getting better though. After products like Snowflake have demonstrated how much better our developer experience can be by essentially putting a VM on top of S3, the traditional data lake design is finally evolving. In the age of the "great data tool decoupling"(Wes McKinney™), data lakes are meant to evolve into a more expressive architecture called the Data Lakehouse: data can be kept on cheap object storage in open file formats, while applications can be built with processing layers that are tightly optimized for different use cases (ETL, analytics, business intelligence, data science and machine learning). Instead of doing everything in Spark, for instance, we could finally dream of much simpler ways to run a mix of SQL and pure Python - at least for all those workloads that do not involve grandiose scale.
The Data Lakehouse offers the opportunity to rethink a lot of the infrastructures built in the past and dismantle a lot of the distributed systems architecture into simpler and more intuitive models. And hopefully, we will be able to finally pay the developer experience the attention it deserves.

The ideal developer experience for data: the thing with feathers
The best developer experience in the cloud is the one where we don’t see the cloud. It might sound a bit like a geeky version of the Heart Sutra (“the cloud is nothing more than emptiness, emptiness is nothing more than the cloud”), but I believe it’s true.
Allowing developers to focus solely on their code makes it easier to be productive. For instance, it becomes easier to jump into new codebases and systems we haven't built ourselves.
Focusing on developer experience also makes retention higher and ramp up costs lower, which is undeniably good, even if it is often hard to measure for execs. 1
In our view, this experience can be captured by many features of the Serverless/FaaS paradigm. Let’s start with a disclaimer since serverless is an ambiguous term that can mean different things to different readers. For most people, serverless immediately means AWS Lambdas (or their GCP and Azure homologous) and the cost structure associated with them.
👉 However, that is not what we mean. When we talk about FaaS, we mean a kind of developer experience that abstract away most of the infrastructural chores like resource provisioning and configuration, containerization and environment management, while retaining the compute elasticity of the cloud.
Our ideal developer experience for data in the cloud would be something along this lines:
FaaS. Because data pipelines become more complex and articulated, the steps that compose them have different infrastructure requirements. Ideally, we would want the ability to allocate CPUs, GPUs, memory and network per function rather than per workload without having to go deep into stuff like containers and Kubernetes.
Fast feedback loop. No one likes to develop on a system in which it takes 10 to 30 minutes to see a change in our code. The ideal time frame is below that cognitive threshold that makes us feel the urge to check Slack and get irremediably distracted from what we are doing.
Multi-language. SQL has been gaining ground in the data science and machine learning community thanks to the last generation of cloud data warehouses, but Python remains the lingua franca for a lot of very important use cases. Ideally, whether our building blocks are SQL queries or Python functions shouldn’t matter to the developer.
REMOVING ONE REASON TO WORK ON YOUR LAPTOP
If we now turn to what the industry offers with this developer experience in mind, we can find several recent advances that can help us build it. The first thing we might want to do is address the feedback loop, the first reason we choose to develop locally. How do we make feedback loops in the cloud comparable to our local machines?
In-memory query engines
One very important thing that happened in recent years is the birth of highly embeddable columnar database engines. Take DuckDB, for example, since it is gaining popularity pretty quickly for good reasons. It provides an in-process OLAP database with a pretty fast execution engine, very simple client APIs for other languages and compatibility with open formats like Parquet, Iceberg and Arrow.
The main point of such a system is that it is fully embeddable within a host process, which basically means no external dependencies for compilation or run-time. This is a big deal because we can now embed DuckDB as a query engine and run it over cloud object storage like we would run a script on a file on our local machine.
Arguably, because we are actually in the cloud we are able remove the bandwidth bottleneck, which is one the main limitations when working with sizable datasets. Basically, instead of moving the data to the engine, we can bring the engine to the data. All this makes DuckDB pretty easy to embed in a serverless cloud experience. If you want to see how simple it is to use DuckDB as a query engine in a lambda check our repo here.
It might not be the most stable project in the world yet and it might be a bit too early to bring it into very critical applications today, but it indicates a direction that the industry is taking. In general, the dawn of projects like DuckDB, Velox, and DataFusion signals that high performance OLAP capabilities are becoming embeddable in a wide range of applications and that simpler cloud native developer experience for data can be built on top of object storage.
FaaS for data pipelines
Unfortunately, as far as runtime is concerned, having fast embeddable query engines is not the end of the story, especially with data pipelines. The main problem remains how to build an optimal system that can leverage all these great tools in the context of building sizable data workloads.
Even if we wanted to use something like DuckDB, our ability to build a delightful FaaS experience in the cloud will boil down to how we run it. The choice would roughly be between:
i) Cloud products (e.g. AWS Lambdas).
ii) Open source frameworks like OpenWhisk, OpenFaaS, K-native OpenLambda, etc.
iii) A combination of an Orchestrator (Airflow or Prefect) + Docker + Kubernetes.
We talked about AWS Lambdas, open source frameworks and new cool kids in our last post, so we won’t go over the argument again. So let’s talk about the more traditional set up where developer experience is designed around DAG-first frameworks, like Airflow.3 In our experience, this is by far the most widespread design.
We could leverage their open source nature and add custom code to accomplish our goals: for example, we could augment docker primitives in Prefect to build and manage containerized environments per function. The problem with that would be that we’re back with having to take care of the runtime ourselves and we don’t want that.4
A possible solution would be to go for the hosted versions, so we won’t have to take care of the runtime directly - Astronomer, Prefect, Dagster, they all offer top-notch solutions to run your DAGs. However, we would not fundamentally change the picture we laid out above as we would still have substantial developing efforts to make sure to have the right abstraction for isolation. When we deal with pipelines, functions are complex and their output bulky: in a data DAG, it is perfectly normal to have a function that outputs a 50GB table and feeds it to several children. If we go to S3 every time a function needs to pass data, it will take forever to run a pipeline. So much for a fast feedback loop in the cloud.
In other words, the main problems remain: our runtime would be suboptimal for running pipelines because function isolation is absolute and data passing would require manual copies to durable storage. In addition, local containerization via full Docker rebuild is still required to modify dependencies, push and deploy changes. This puts too many intermediate steps between the code and the runtime to iterate with the same speed of a local machine.
Are we humans or are we runtimes?
Once again, we are not suggesting that all these frameworks are poorly designed. After all, they constitute the spinal tap of many reliable and scalable architectures out there. More modestly, we are just trying to say that whatever the motivations behind their design was, it is not easy to retro-fit them for exquisite developer experience for data developers.
The distinct impression we have at this point is that many popular cloud data tools are not designed for humans, but rather for machines to run when humans are busy doing something else. For instance, orchestrators are built to run efficiently at scale and reliably during the night, but when we try to develop on them we feel that they force the wrong level of abstraction and a very slow feedback loop on us.
The suboptimal ergonomics of our current cloud setup for data is one of the main reasons for people to develop locally. This apparently innocent sin creates a divide between dev and prod that snowballs into unnecessary complexity, high costs, and widespread inefficiency. It’s a butterfly effect that puts a serious burden on organizations.
Going forward, data workloads will become truly ubiquitous in our applications. Building people-first experience in the cloud is important because it is the foundation to transition into more mature production processes to iterate on our applications more efficiently.
The first thing we need to remove the need to go local is: FaaS with fast turnaround time. A simple way to write and organize our code and a fast way to run it into the cloud (like really fast, faster than our local machines).
In the next post, we will talk about removing the second reason, that is making it easier to collectively work and debug directly on production data, by versioning code and data at once.
Until next time!
1 It is hard to turn DX into measurable KPIs:
but as (allegedly) Einstein used to say “not everything that can be counted counts and not everything that counts can be counted”.
2 Frameworks like Metaflow point to the growing need of decoupling code and infra as much as possible.
3 When choosing your tools it is worth keeping in mind that first-gen Python orchestrators (like Airflow and Luigi) were not designed to move data artifacts around while second-gen ones (like Prefect) are much better at that, although they unfortunately trade in isolation (Prefect).
4 Note that we have used many of these tools while building ML systems including more specialized options like Metaflow. We tried pretty much everything out there before landing on a clear tool chain.