Why we develop on data locally and why we should stop - Part 2


“There isn’t much of a difference between production data and production environment for us I am afraid”
— The VP of engineering of a pretty data savvy late stage startup I was talking to a couple of weeks ago.
In Part 1, I talked about DX and slow feedback loop, as I think it is one of the main reasons data developers choose to work locally instead of the cloud.
Another reason that induces data developers to work locally in my experience has to do with having a simple way to work with production data without affecting the production environment.
Why we need production data?
The distinction between dev and prod in data is definitely fuzzier than in traditional software engineering. The main reason is that production data is often needed even during the development phase, because developers cannot be sure that their work will work against the production environment without testing it against the actual data in production.
Working with data means to essentially work with an open ended system. As a consequence, there are several things that constantly or abruptly change simply because they depend on external factors. A data pipeline that processes user browsing events from an ecommerce website, will deal with unusual distributions and loads on Black Friday. Schema definitions can change for a number of reasons that range from an external API that gets deprecated, or a change in the ETL business logic. All these are very common scenarios when working with data.
The traditional tools for testing code in CI/CD cycles remain fundamental, but might not be enough to capture this open ended element. No amount of unit tests will help shed light on a problem due to a distribution shift, the only way to know is to run our code against the real world.
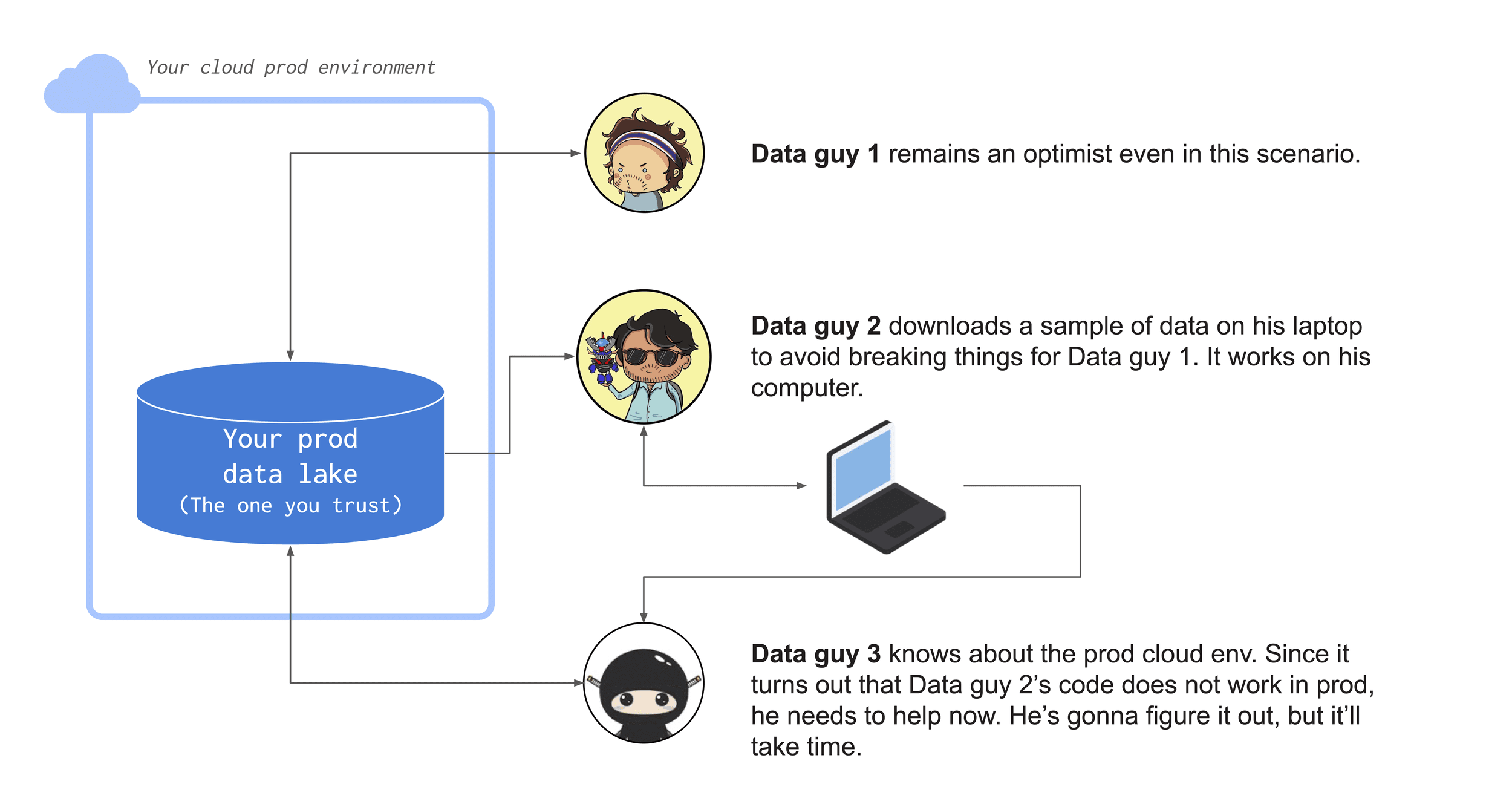
To create a good dev environment one could create data samples or use synthetic data. This is often needed in some industries, like healthcare or financial services, where working with production data involves compliance and legal requirements.
But the truth is that maintaining such environments is a demanding and continuous effort. Because data keeps changing, dev environments quickly become unreliable, giving no assurance that the work done will seamlessly run also in production. Developers have a well-grounded need to work on fresh production data. There is no easy way around that.
This leaves developers with a choice. They can jump to the boarding in the production environment with the risk of making breaking changes that affect downstream consumers in ways that are hard to spot.
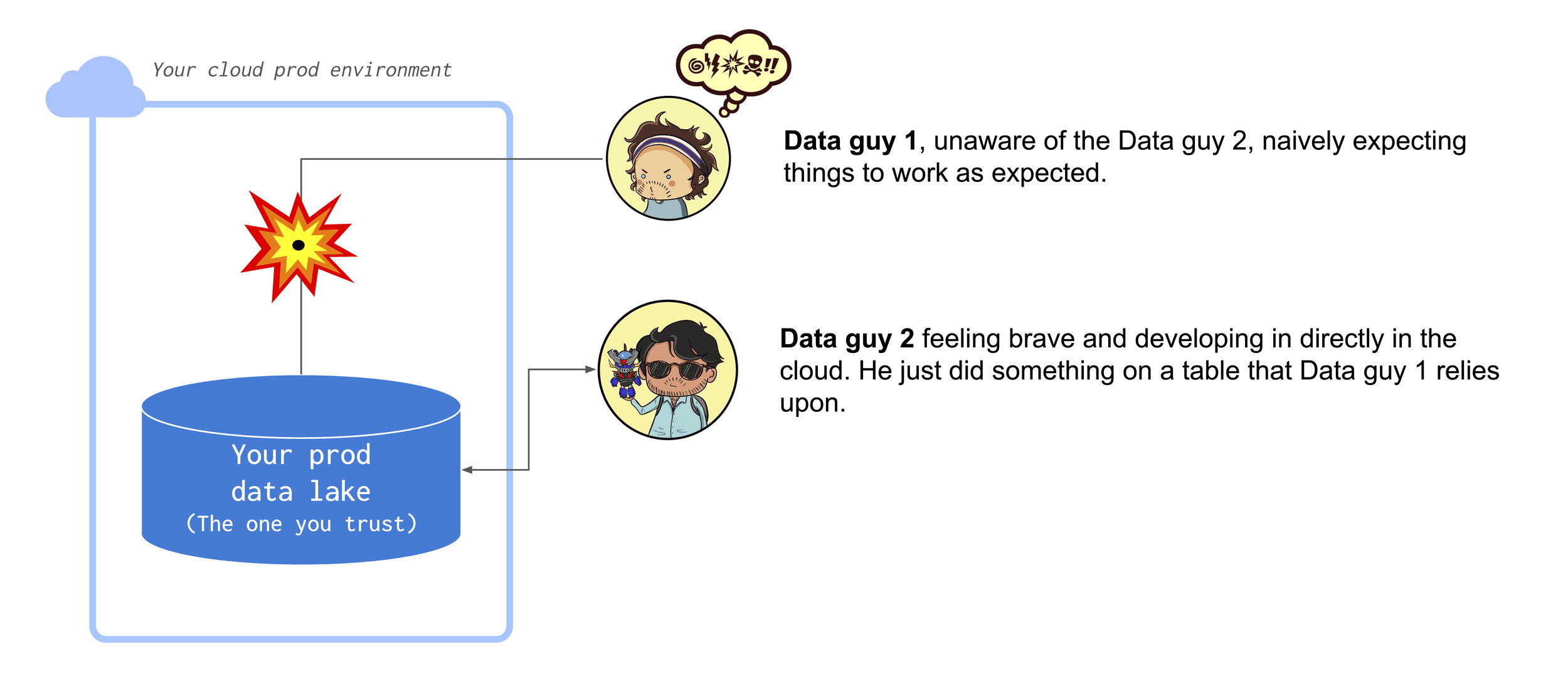
Alternatively, they can download a sample of the data on their local machine doing their best to replicate prod. It will probably always require some work to go to production, but at least it's safer.
Reasonably, most choose the latter. Now, this problem has clearly been solved for code where we all use Distributed Version Control systems like git and abide by good CI/CD practices. Nobody in their right mind would allow developers to change the code directly in prod, but also nobody in their right mind would tolerate code being written only locally.
The ideal developer experience for data: The thing with feathers (reprise)
Because using production data is often a necessity for developers, we would ideally want data platforms to offer a developer experience that facilitates working on real data while ensuring solid guardrails at the same time.
Like Git for data. The important first thing would be to have a simple way to sandbox environments where data can be processed without affecting the production environment. For instance, a version control system for data to easily copy production data into development environments and keep track of the changes. Whatever this mechanism is, it would need to both ensure good performance and be economically sustainable by keeping storage costs relatively low.
Keep track of code and data at once. One thing that makes implementing version control over a data system complex is the fact that data and code are two separate things: the code base is usually managed on platforms like Github, while data is stored in databases, warehouses and data lakes.This separation makes reproducibility hard and debugging convoluted. Let’s say we have a pipeline misbehaving in a certain moment in time and we do not exactly know why. In principle, the problem could lie in the code, in the data or both. To reproduce the issue deterministically we would need to travel back in time in our code base and in our data, but because there is no system that keeps track of these two things at once, it takes a while to figure out a way to reproduce the issue in a way that is easy to understand. A good system would ideally allow easy time travel for both data and code. (1)
A system built striving for this developer experience would be a principled way to incorporate well understood practices of software engineering into data systems, as it would recognize that the relationship between code and data is complex because data systems are inherently open ended.
Removing another reason to work your laptop
Let us now turn to the most recent advances in the industry for some help in building such developer experience. The good news is that a lot of progress has been made recently, so the pieces are almost all there. I am not going to lie, it’s a headache to make all the pieces work together. At the current stage, there is no still no simple system that just comes out of the box and takes care of all of it, so in the end the specific choices will depend on our use cases and tradeoffs.
In any case, to give developers a simple way to work securely on production data, we will have to address at least how to:
- Copying production data into dev environments.
- Choosing the right data format to support git capabilities.
- Come up with a version control abstraction that is simple to use.
Zero copying and (not) moving data around
Do you remember the Modern Data Stack? (2) We talk a lot less about it these days, but there are many good things to learn from it. We can discuss what exactly makes a stack “modern”, but one very good thing about that design is that, among other things, it introduced version control for data, mostly thanks to the fact that Snowflake has Zero Copy Cloning and dbt helps expressing workloads as pure code.
Zero copy is what is most interesting here. In essence, zero copy allows data to be transferred between applications without being copied from one memory location to another. Instead of creating a full replica of the data, zero copy creates new metadata information pointing to the source data.
When we query a table, the data fetched may either come from the original source or from some newly created tables that are not in the actual source. The final layout of where the data come from will depend on what we need to fetch in order to satisfy the query, but as users we do not know, because all this is abstracted away through a metadata layer. This means we can clone large tables without incurring in computation and performance costs to move data around, and without multiplying our storage costs exponentially.
Now, this is hardly a new idea, but some way to implement the equivalent of zero coping is a necessary step to build a compelling version control developer experience for data, because it is essentially the only way one can guarantee good performances and reasonable costs for data intensive systems.
Open table formats and data versioning
All this is pretty easy if we are using a product like Snowflake, but if we want to implement the same concept on a data lake, things are (unsurprisingly) more complicated. (3)
As a matter of fact, there still isn’t a simple way to have a decent version control experience on a data lake, and frankly most companies I know are not even at the point of having zero copy capabilities on their data lake.
The good news is that things are getting much better thanks to Open Table Formats like Apache Iceberg, Delta Lake and Apache Hudi.
We will not go into a feature comparison of these formats, since there is extensive documentation from all three projects and there is already some pretty good material on the topic.
It might just be worth saying that the strongest open source community seems to be around Iceberg right now, so there might be a potential strategic benefit in building upon that, even just to future proofing your architecture and avoid being locked up in one single ecosystem.
The general point about open table formats is that they provide a metadata layer which functions as a table abstraction over data lake storage: instead of dealing with files, we can deal with tables like we would do in a database. The metadata layer contains information that query engines can use to plan efficient execution. A good table abstraction ultimately boils down to:
- Guaranteeing Atomic Transactions: make sure update/append operations don’t fail midway leaving the data lake in disarray.
- Handle Consistent Updates: make sure reads do not return incomplete results during writes and provide a way to handle concurrent writes.
- Allow SQL analytics: let query engines like Spark, Trino or Dremio work directly with the data lake, as if it contained tables that can be queried multiple times in the same moment.
What is important here is that these formats allow us to keep track of table changes over time and effectively implement time travel. While the data of the table is held in immutable Parquet files, changes are saved as metadata and file stats, manifests or logs (4), from which the latest status can be reconstructed when the data is accessed in order to calculate a version of the table.
Developers can use open table formats to have read-only access to different versions of the table at different points in time, without having to make hard copies of the data over and over.
This, as we discussed, is a crucial property for every system aiming at enabling git-like semantics for data and guaranteeing easy reproducibility, because the same mechanism can be used to zero copy data while developing.
Data Version Control
The last piece would be to actually implement a version control system to track datasets changes and give developers the possibility to interact with such system as intuitively as possible, for instance by using git-like operations like branching, checkout and merging.
A data version control system is essentially an abstraction for humans to collaborate on a complex project.
It is really not easy to devise an optimal design for that, as it requires finding the delicate balance between user-friendly simplicity and the flexibility to manage projects of potentially unbounded complexity.
When we talk about data, we need to add that we are trying to do it for an open ended system where things can change, sometimes predictably and sometimes abruptly, sometimes for grounded reasons and sometimes…well, because stuff breaks.
At this level of representation it is important that the system provides good abstractions to address business problems. For instance, we might be trying to build isolated test environments for continuous deployment, or we might be trying to implement WAP for our ingestion pipelines, or we might be trying to provide data scientists with a more ergonomic way to develop against production data, so they don’t use their laptops all the time.
Probably the most mature data version control systems out there are Project Nessie and LakeFS. In general, whatever choice we go for, we will need to take care of the following things.
- Keep track of versioning over complex collections of artifacts (like pipelines, repos or projects rather than single tables).
- Implement git-semantics for data artifacts resembling the one all developers are already familiar with. That is:
- Branch: get a consistent copy of the production data, isolated from other branches and their changes, as a metadata operation that does not duplicate objects.
- Commit: set an immutable checkpoint containing a complete snapshot of the data.
- Merge: atomically update one branch with the changes from another.
- Roll-back: go back in time to the exact state of a previous commit.
- Tag: a reference to a single immutable commit with a readable, meaningful name.
It is worth keeping in mind that this is a further level of representation compared to table formats.Open table formats provide the metadata and the hooks upon which good (or bad) abstractions can be built.However, the relationship between these two levels sometimes depends on how frameworks are designed. For instance, both LakeFS and Nessie enable git-like operations over collections of data, but while Nessie depends on the metadata created by the Iceberg data format, LakeFS leverages its own independent data model that makes it more format agnostic.
At the same time, lakeFS represents repositories as a logical namespace used to group together objects, branches, and commits which makes it less aware of table and file formats and more similar to a versioned object store rather than a fully-fledged data catalog.
Choosing the right level of abstraction for a Data version control system will then depend on a number of considerations about usability, processes and ability to integrate with other parts of the stack.
Consider the Octopus: A plea for better Cloud DX
Octopuses have distributed brains. There are local brains on the tip of the arms each of which is capable of acting independently - able to taste, touch and move in its own direction -, and then there is the central brain which deals with higher level functions and is able to exert top-down control. This is the reason why a detached octopus arm can independently move and even grasp food.
Most data organizations I have seen are conceptually organized as an octopus brain. Data science, analytics and machine learning teams can make independent business or product decisions, while the platform team can maintain control on the entire system, make sure that data is in good shape for everyone, and make strategic decisions about the stack. This model aims at giving freedom while maintaining control.
Albeit counterintuitive, local development disincentivizes this type of decentralization. The developer may see local development as an effective way to get things done, but the divergence between the environments make the process to bring things into production much longer. Essentially, platform engineers are required to be involved in more processes than it would be needed because they are the only ones that know the production environment well enough to be able to deploy securely.
So instead of having the central brain focus on top-level control only, we have it weighting in on many of the actions that the peripheral brains should make individually, making our octopus slow and frankly confused.
Local development also makes working collectively hard, because every developer will choose a different set up and many things will depend on how good they are at building a local environment that resembles the production one. Especially in data science and ML, that varies a lot because some data scientists are more familiar with software engineering than others and the variety of libraries and tools is staggering.
A very solid argument in favor of local development is, of course, costs. However, when organizations become complex, even this argument becomes less obvious as it initially seems. It is true, the cloud is more expensive than our laptop when we look at the bill, but under the right circumstances this can become a myopic way of thinking about costs.
When an organization becomes complex enough to have several orgs connecting into a central platform team, keeping the bill low is only half of the problem. The other half is the hidden cost of complexity, of inefficiency and of opportunity cost.
So when you think about your data platform and the development practices that you want to implement in your organization, consider the octopus.

A data platform team hiding from downstream consumers.
Footnotes
- Such a design would also be good for auditability and incident handling (can we identify quickly what went wrong and roll back?). Moreover it would help implement fine-grained governance policies (can we determine quickly, what datasets were affected by whom and when?). Both auditability and governance are critical areas, especially for big enterprises and for highly regulated industries.
- I am not a great fan of excessively convoluted industry taxonomies, but we can think of the Modern Data Stack as dbt + a cloud data warehouse + some way to deal with ingestion from a multitude of sources + BI tool.
- For cloud-based solutions more vendors are providing database branching out of the box. For instance, Neon provides a delightful experience with postgres branching.
- Different formats will have different ways to do that.




