Data engineer agents




Agentic data workflows
View on github.
Recently, there have been many announcements around "data agents" that can take care of tasks performed by data teams, like creating dashboards, writing SQL queries, and even doing advanced data science. These agents are very impressive but they typically operate within a tightly controlled perimeter, running in notebooks and using local files.
Production workflows do not work like this.
- First, real-world data workflows span multiple phases: ingesting files, cleaning and preparing data, testing for quality, building analyses, training models, creating dashboards, optimizing pipelines. In practice, these tasks are not handled by a single person. Instead, they are split across two teams: data and platform engineers on one side, analysts, and data scientists on the other. Each role works in different parts of the stack, often using different tools, abstractions, and mental models.
- Second, data engineers and data scientists need to be able to work with large datasets that do not fit comfortably on local machines and require cloud infrastructure for compute, storage and data management.
At Bauplan, we believe that AI agents will radically reshape the way developers interact with the data stack, especially in workflows that are today fragmented across roles. Just like how DevOps changed the boundary between development and operations, we expect agentic systems to blur (or even automate) many of the traditional handoffs in data workflows.
To solve real-world, production-grade data problems, agents must be grounded in systems that provide a reproducible execution context, programmatic access to data lifecycle operations, and a composable API surface with stable semantics.
To make this possible, we need three ingredients:
- Real-world use cases, both in the form of questions (what needs to be done) and answers (how it actually gets done today).
- LLM APIs to power the agentic flow - not just as model endpoints, but as programmable interfaces for incremental reasoning, structured retries, and constrained tool use.
- Data infrastructure built for agents. Agents need a reproducible execution context to iterate on the data to isolate and control their impact, and simple APIs to make code generation easy.
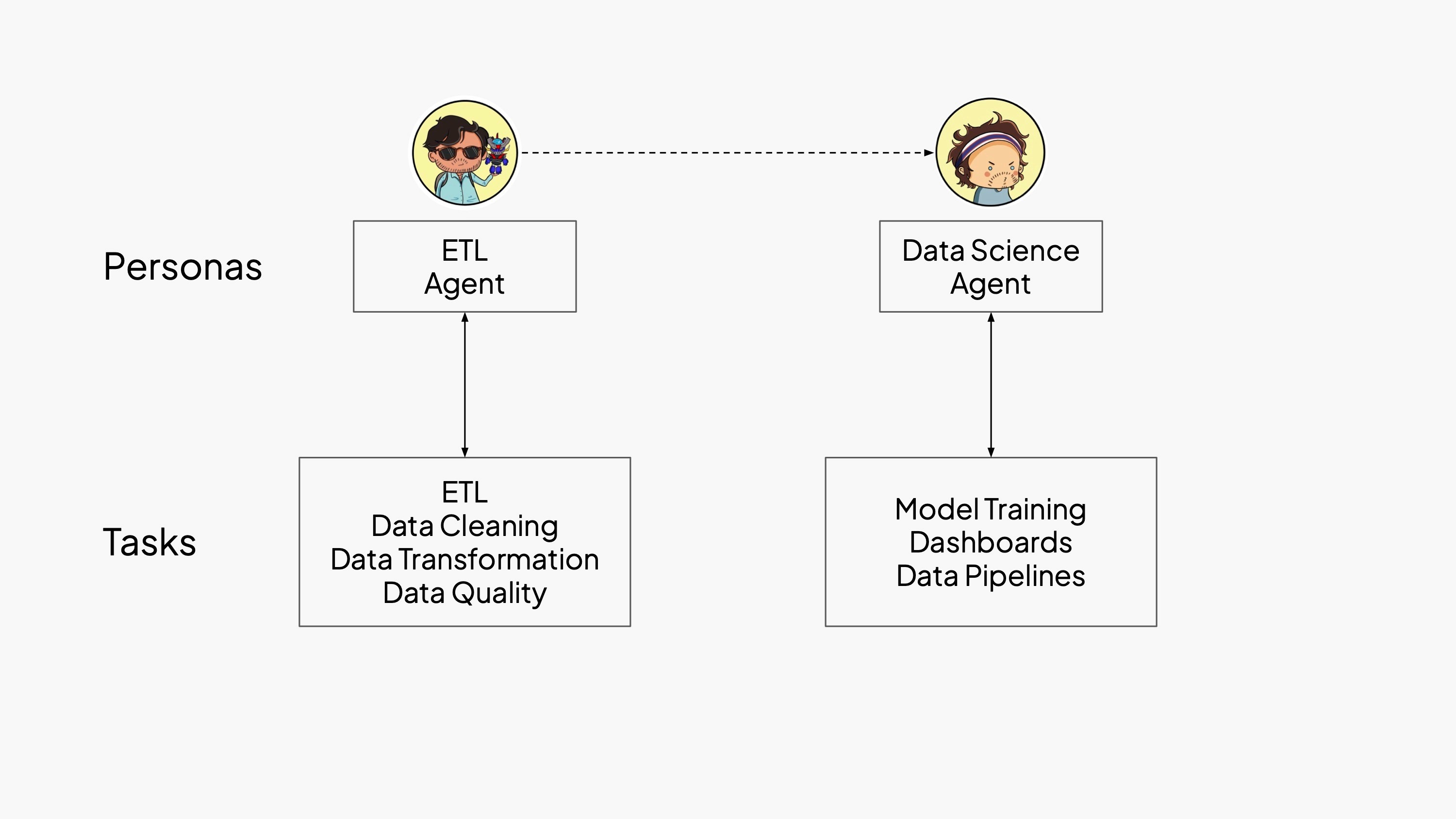
We partnered with Together and Adyen to build two agents that mirror the current division of labor in data teams:
- one agent is focused on data engineering tasks — like ingesting and preparing cloud data
- another one is focused on analysis and modeling.
These agent roles reflect the same specialization found in human teams, but now executed autonomously so developers can supervise end-to-end workflows instead of managing each step by hand. In other words, we designed an agentic data stack.
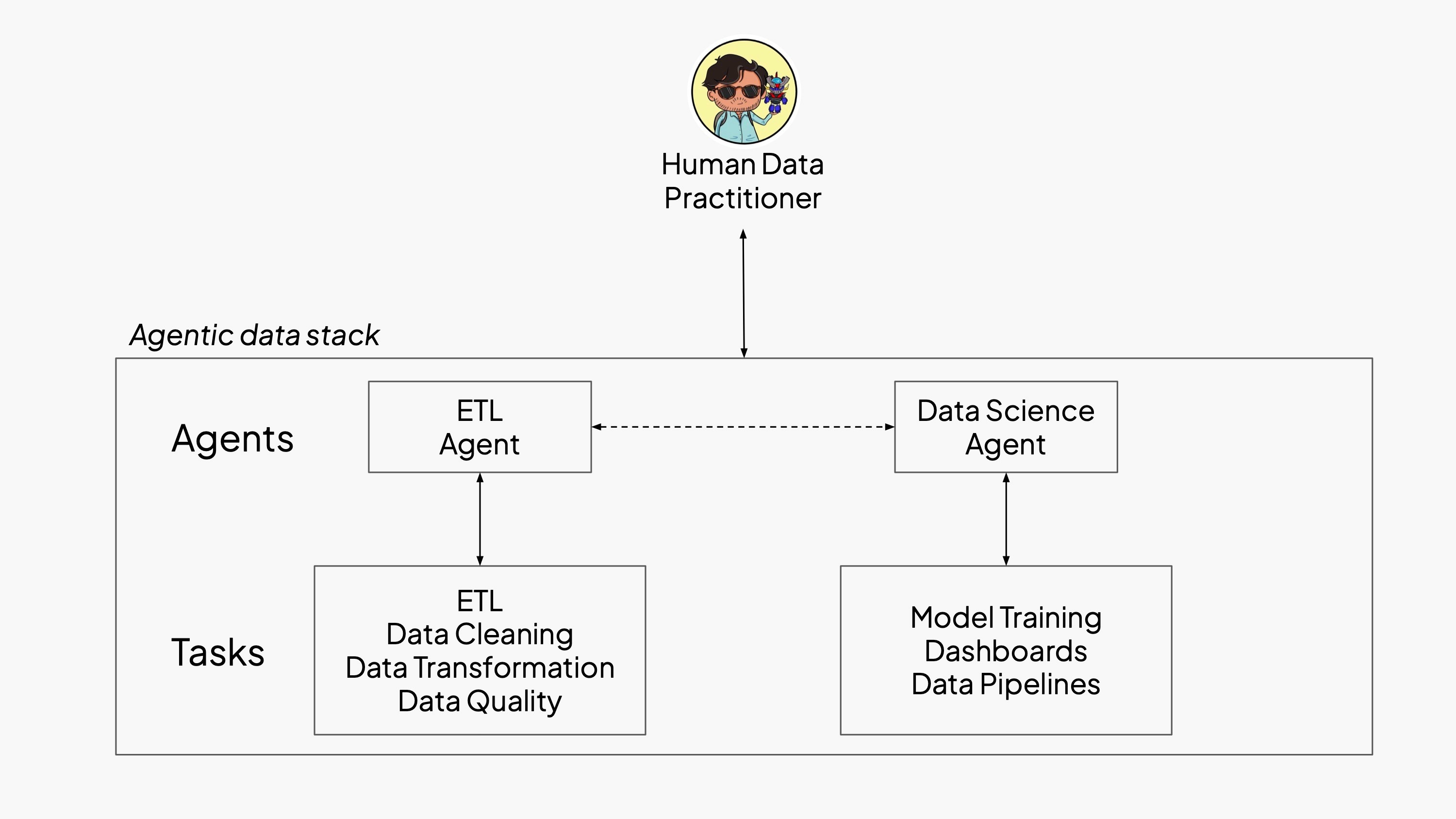
This is the first installment in a two-part exploration.
- In Part 1, we introduce a data engineering agent designed to tackle the least-glamorous part of the lifecycle - cloud-native ETL - with production-grade infrastructure.
- In Part 2, we’ll turn our focus to a data science agent that builds on this foundation to perform downstream analysis and modeling tasks.
This is a very practical piece of content. There is code you can run, datasets you can reproduce and verification tests you can expand and improve. We want you to see first-hand what can be done today and have a glimpse the future we are building.
So clone the repo and dive into it.
The cloud ETL agent
This ETL agent is designed to operate under real-world production constraints. It runs on scalable cloud infrastructure, pulls raw datasets directly from S3, executes logic inside reproducible containerized environments, and writes to isolated, versioned data branches. This ensures full observability, deterministic execution, and safe rollback.
The Dataset
Since we are focused on production, we use Adyen’s DABStep project. This dataset is a collection of real-world, multi-step business questions rooted in transactional payment data. Unlike synthetic benchmarks, DABStep captures the ambiguity and trial-and-error typical of real analytics work. Many questions require more than just SQL: they demand reasoning across tables, parsing raw files, filtering edge cases, and combining text, numbers, and time. Iteration is fundamental to a real-world scenario, so overfitted benchmarks won’t cut it.
Workflow and agent loop
The ETL agent follows a ReAct-style loop. ETL is a natural fit for ReAct because it benefits from step-by-step reasoning: the agent can incorporate partial feedback - like schema mismatches, access errors, or broken records -, and iteratively refine its approach. This makes the workflow robust in the face of the uncertainties that always come with raw, cloud-native data.
At its core, each turn of the loop is simple: the model “thinks out loud,” generates code, runs it in a controlled environment, inspects the result, and tries again if needed — until the job is done.
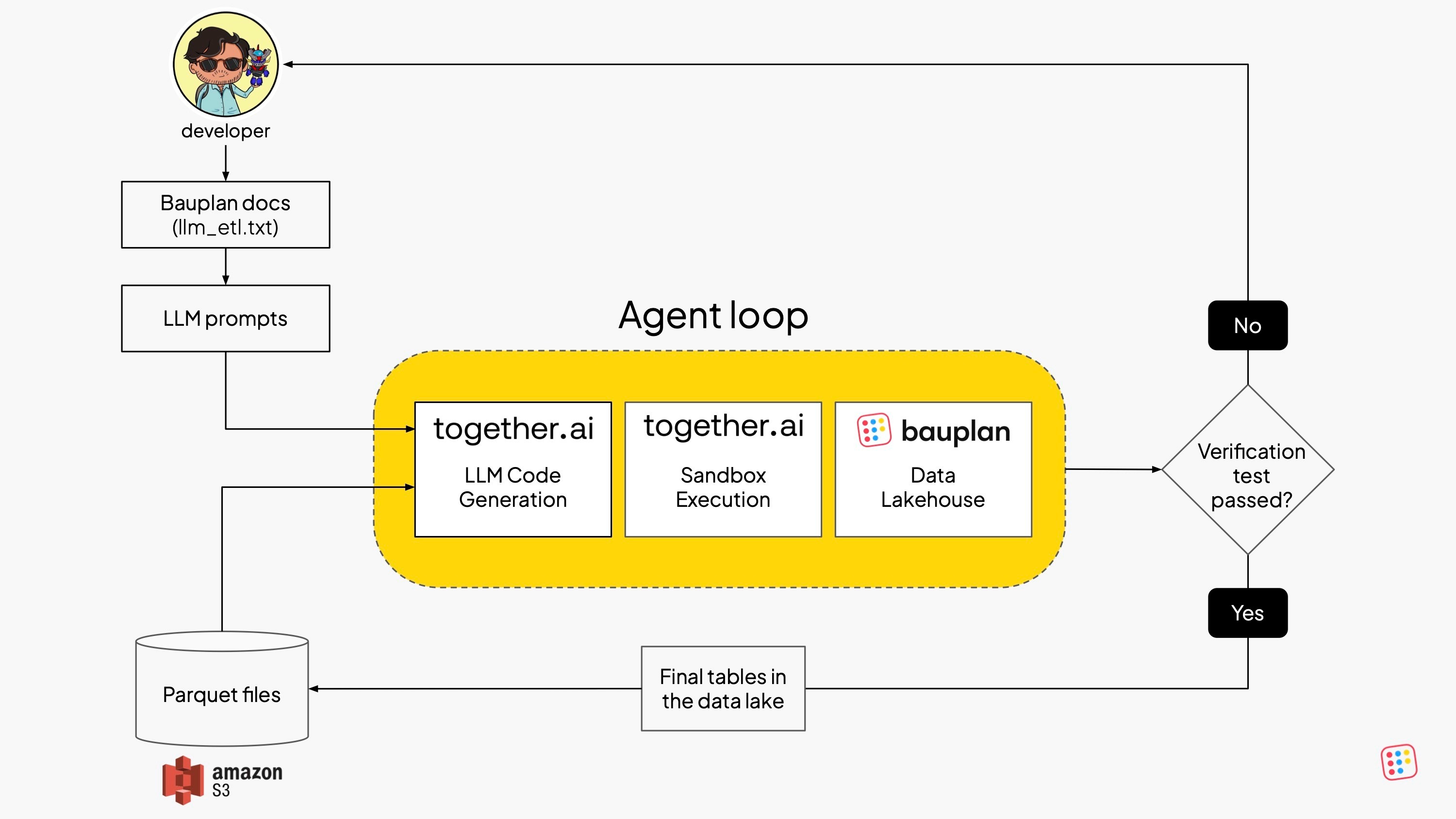
The system is structured as two tightly connected loops: one for generating and executing the ETL pipeline, and another for verifying the data assets produced. The flow is deterministic, modular, and relies on a minimal set of composable components:
- Model loop — A Together AI-hosted LLM receives a structured prompt describing the dataset and the goal. It returns Python code in a strict format, including reasoning, required packages, and code blocks.
- Executor — The code is parsed and run inside a Together AI cloud sandbox with access to the necessary packages, S3 files, and Bauplan’s Python SDK.
- Data platform — The generated code uses Bauplan to manage branches, create tables, run queries, following a Write-Audit-Publish pattern.
- Verifier — A simple Python script checks the resulting tables: do they exist? Are they populated? If not, a human developer needs to step in.
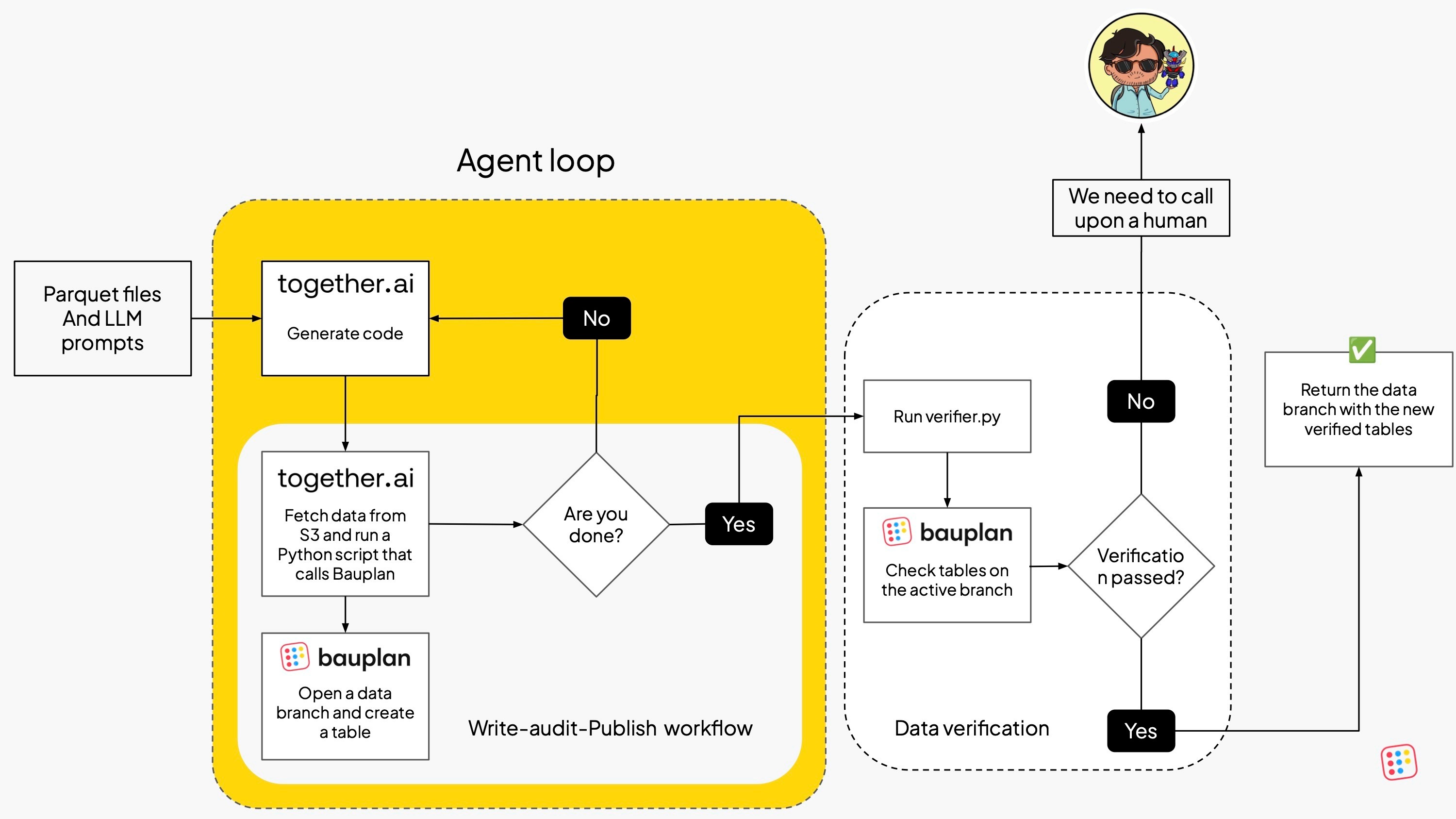
Most runs complete in 2–4 turns: the LLM revises its code based on stdout and stderr from the sandbox, until it reaches a “fixed point” in which no further improvement is needed. Once certified by the verification script, the tables are considered ready for the next step (i.e. data analysis).
This approach is composable and resilient at the same time: the model, the sandbox, and the verifier are all modular. If we want to swap the model, tighten the verifier, or extend the checks from row counts to schema constraints, we can do it without breaking the overall loop. That’s the foundation for an agentic workflow that runs under real cloud constraints, rather than simple local demos.
The prompt
We wrote a simple prompt including detailed instructions, inline context about Bauplan, and guidance for interpreting verifier results. Importantly, the prompt includes a condensed version of Bauplan's documentation: just enough context to help the model generate syntactically valid and semantically meaningful code.
The ETL workflow produced by the agent
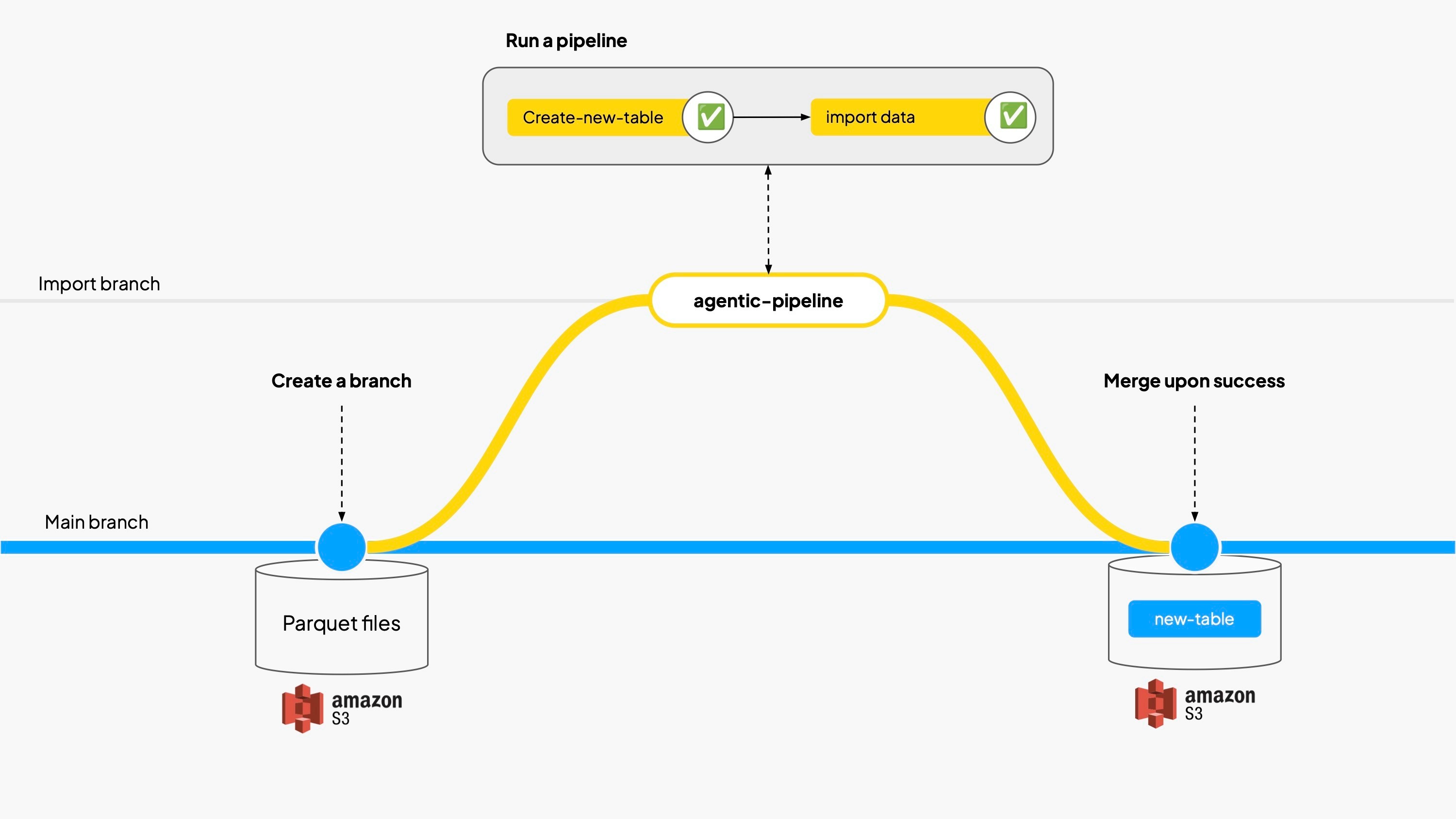
What does the LLM do with Bauplan? On most runs, the agent autonomously decides to implement a Write-Audit-Publish workflow using Bauplan’s data branches to avoid corrupting the main data lake. Basically, the code written by the model is:
- Create an import branch in Bauplan.
- Load Parquet files from S3.
- Materialize the data as Iceberg tables into the import branch.
- Check the tables and merge if all looks good.
Most runs complete in 2–4 iterations: for ease of comparison, we published a snippet produced during our runs here. Even open source models manage to discover and use correct patterns: data gets loaded into a scratch branch, validated, and only then committed.
This is a very important point because running untrusted code safely on a traditional data platform would require a non trivial amount of work to set up a dev environment with sample or synthetic data. Simply put, we wouldn’t have a safe, reproducible, and scriptable environment where an agent can iteratively experiment without risk.
Because Bauplan allows branch-based data development and exposes the entire data lifecycle in a unified Python-native SDK, the agent can build a functioning, cloud-native, end-to-end ETL pipeline starting from nothing but files in S3 and a short prompt.
Composability and Modularity
This project is more than a one-off ETL demo. It’s a template for building agentic workflows that are modular. So, at every layer they can be composed, and if needed, swapped.
Each layer is pluggable:
- Models can be swapped with LiteLLM, letting us choose easily between the closed source models and all the endpoints provided by Together.
- Execution runs in isolated sandboxes, abstracted by a simple class. While we use Together's code interpreter, the repo also hosts another implementation of the same class to showcase the project modularity.
- Lakehouse APIs could change so other data platforms can be plugged in - although Bauplan’s has strong advantages for agents (see below).
- Verification logic is also modular: it can be programmatic, manual, or even LLM-generated, although in some cases the “data merge” would be more appropriate if done outside the loop, and together with the verification. That flexibility allows teams to trade off safety, speed, and autonomy depending on their needs. Today, the verifier logic is shallow (we should check schema, semantics, and lineage, not just row counts), but it is easy to extend.
This modularity is very important because AI tools are evolving fast, and we need infrastructure that adapts. Our collaboration with Together is grounded in this philosophy: we prefer open loops to closed silos, because they let us use better models without rewriting the stack.
The agentic data platform
Whether you are a data engineer or a data scientist, if you want to operate in production, you need a data platform to perform critical tasks reliably and at scale. That means:
- Executing pipelines on scalable compute, not local machines
- Managing and versioning data stored in cloud object storage
- Applying transformations in a reproducible and auditable way
- Monitoring execution and handling failure modes (timeouts, retries, partial writes)
- Enforcing governance constraints like access control, schema validation, or publishing gates
Agents are not different: they need a data platform designed around their constraints.
Bauplan offers three core affordances that make agentic workflows not only possible, but practical:
1. Code-first, Python-native design. Agents generate code, and in Bauplan, everything - from data ingestion to lifecycle operations - is expressed in Python. There’s no need to juggle SQL, YAML, CLI tools, or GUI forms. That reduces hallucination, simplifies control flow, and gives agents a consistent language to operate in. Unlike traditional platforms, where scripting, orchestration, execution and data management live in different layers, Bauplan offers a unified, scriptable surface.
2. Git-for-data and data branches. Agents make a lot of mistakes. They guess, retry, and learn by iteration. That means they need isolation, rollback, and version control to avoid being disruptive. Bauplan gives each run its own data branch, and nothing reaches production until explicitly published. This isolates failures, allows checkpoints, and enables reproducibility. Few platforms offer this kind of sandboxing, and even fewer expose it as composable, inspectable code.
3. Minimal, deterministic surface area. Our SDK is intentionally small and composable. That makes it ideal for agents: less to learn, fewer tokens to spend, and easier to verify. Code written by the model is less likely to be brittle or wrong when the semantics are predictable.
Put simply: Bauplan’s ergonomics aren’t just human-friendly, they’re agent-friendly. To test these ideas, we focused on a critical but often overlooked piece of the data workflow: cloud-native ETL. On the “agent loop” side, TogetherAI made our life easier thanks to the inference and sandbox offering, which work out of the box with a Pythonic framework such as Bauplan.
This project shows that agentic ETL is not only possible, but practical, laying the foundation for Part 2, where we’ll explore how agents can interact with metadata, branches, and table schemas to answer real business questions.
Until then, you can clone the repo, run the agent, and try your own verifier. If you make it better, let us know: the whole point is to figure this out in the open.
Acknowledgments
Thanks to Martin Iglesias Goyanes and Friso Kingma for their constant support on how to best leverage DABStep, and to Marco Graziano and Davis Treybig for helping with the article.




