Python Over Data Lakes


Python over data lakes
Two weeks ago, we had the chance to share what we’ve been building at Bauplan at Data Council in Oakland, CA. It was an honor and a lot of fun.
The engagement has been amazing, and we’re thrilled to see our ideas resonate with so many data practitioners, especially around Python. Since many folks reached out after the talk asking for the slides, we thought it made sense to share a short write-up of the key ideas. Hope you enjoy it!
AI Got Easier, Data Didn’t
In 2017, we were a small startup building a search engine powered by NLP. At the time, most data scientists worked in notebooks and produced dashboards.
Our job was different: we needed to operationalize machine learning as part of a software product, which meant building an ML system end-to-end—training, serving, retraining, and integrating it into real application logic.
Fast forward to 2025, and a new class of applications has emerged: conversational agents, co-pilots, document assistants, RAG systems. What they share is that they’re built on top of LLMs and designed for end users. These aren’t internal dashboards or back-office models—they’re embedded in real, user-facing software. They need to run reliably, update frequently, and interoperate with business logic, APIs, databases, and user events.
Moreover, pre-trained models are now available through APIs, which shifts the challenge from modeling to software engineering. In many cases, we no longer need to collect training data, tune hyperparameters, or manage GPU infrastructure. We call an endpoint, send a prompt, and get a state-of-the-art result. It’s not about building ML systems from scratch anymore but rather about integrating intelligence the same way we’d add payments or notifications to our app.
Of course, this doesn’t eliminate the need for data and ML expertise: data quality testing, custom models, fine-tuning, performance optimization, and production-scale data workflows still require specialized skill.
However, for many teams, especially early-stage ones, ML has become something they can build with, not just build.
In Search of a Python Data Platform
This shift has made data infrastructure more central than ever, because even if we might not be training as many models as before, but we are still doing the work to make models useful: collecting data, preparing input data, versioning datasets and prompts, evaluating outputs, logging feedback, retraining on fresh data, etc.
Production systems aren’t made of prompts they’re made of pipelines, and while AI got easier, data kind of didn’t, especially for these use cases.
Most of those pipelines for AI are in fact written in Python (at least in part), which is different from analytics and BI where SQL can be enough for everything.
Python in fact soared in popularity in the past years because of AI. It has become the default language for interacting with models, expressing business logic around data, and deploying intelligent features. Whether we are filtering datasets with Pandas or Polars, vectorizing inputs with NumPy, or wiring up an LLM pipeline with LangChain, Python is the glue holding AI applications together.
And yet, oddly enough and despite Python’s dominance, there still isn’t a truly Pythonic data platform.
Today, developers who want to build pipelines in Python mostly turn to orchestrators like Airflow. Nothing wrong with orchestrators, but we need to keep in mind that they were built to solve coordination problems, like scheduling tasks, managing dependencies, handling retries and alerting on failures. They excel at defining when and in what order steps should run, but they’re not data platforms in the full sense: they don’t manage the runtime, the environments, or most importantly, the data lifecycle. They assume that someone else (YOU) is managing:
- where and how our code runs,
- which version of Pandas, NumPy, etc. are used,
- and how inputs and outputs are versioned and stored.
In practice, what we see most of the times is that instead of just coordinating orchestrators end up absorbing a lot of the business logic itself, which gets crammed inside the DAGs, tangled with scheduling and config. Instead of separating concerns, our data platforms becomes a loosely paired mash up of orchestration and execution layer:
- Business logic gets packed into DAG nodes. Because orchestration and logic now live in the same file, it becomes difficult to test or reuse functions outside the DAG context.
- Local dev doesn’t match prod. We can prototype logic locally, but in production it’s wrapped in decorators, mixed with config, and deployed in different environments, making behavior hard to predict.
- Environment and dependency management is coarse-grained. In order to avoid performance to degrade too much, orchestrators typically assume a global image or shared environment, instead of per-task isolation. That makes pipelines brittle to change and harder to evolve safely.
- Reproducibility really hard to attain. Most data platforms simply do not capture a full snapshot of the code, data, and environment for each run. There’s no native versioning or rollback. If something breaks, debugging means digging through logs and guessing who ran what and when.
Towards a Pythonic data platform
There's a city in my mindCome along and take that rideIt's alright, baby, it's alright. And it's very far away, but it's growing day by day And it's alright, baby, it's alright.
Talking Heads, Road to nowhere
Alright, so taking a step back let’s start with asking what’s the smallest, most ergonomic setup we would need to make it easy to deal with data pipelines and data ops directly in Python?
Functions over Tables
This is the general architecture we landed on:
- Storage: object storage (e.g. S3) for raw and structured data
- Execution: containerized serverless functions to isolate and scale Python logic
- Structure: Apache Iceberg tables for consistency, schema evolution, and table-level operations
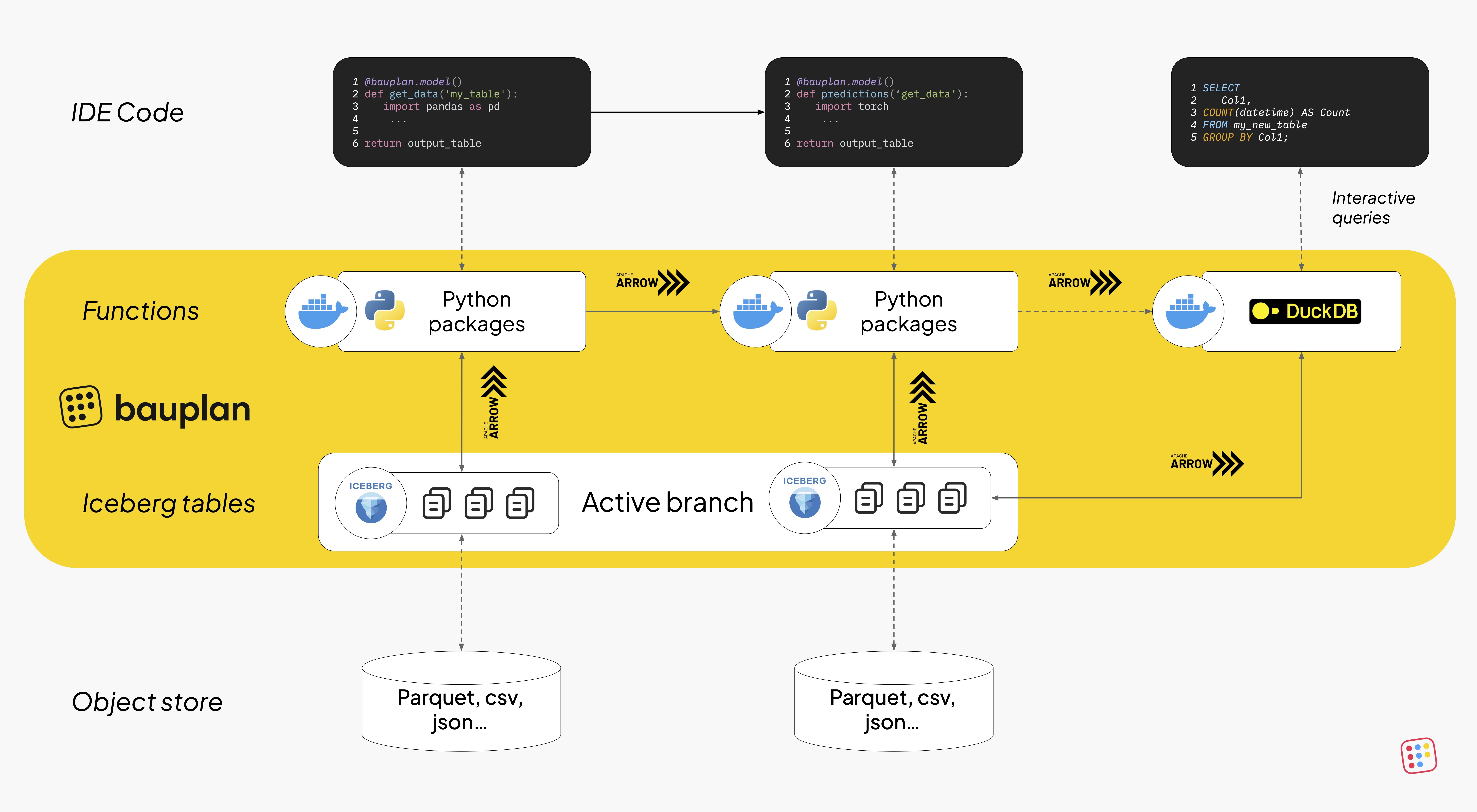
This architecture lets developers write pipelines the way they write software: isolated, modular, testable functions with clean inputs and outputs directly in Python. Each function declares:
- Its inputs (Iceberg tables living in S3 with optional filters and projections)
- Its environment (Python version + pip dependencies)
- Its outputs (new tables as return values consumed by other downstream functions)
Here’s a concrete example. Say you want to compute top NYC taxi zones by number of trips. We can do it with pandas:
We can run this function in the cloud as a function as a service (FaaS) by calling a run API:
In this way, logic lives in simple, composable functions. Each can be developed, tested, and reused like any other Python module, with clear inputs, outputs, and without tight coupling to the orchestration and scheduling logic handling the workflow. This model addresses core problems we explored earlier:
- Business logic stays separate from orchestration. No need to tangle transformations with scheduling and config.
- Local development mirrors production. Functions run the same way in CI, on schedule, or locally without surprises due to infrastructure.
- Environment and dependency management is scoped per function. You can evolve one step without breaking others.
- Reproducibility becomes more achievable. Because functions are isolated, they’re easier to track, test, and rerun.
In fact, if we wanted to change this step completely and use DuckDB instead of Pandas, it would be a pretty surgical change in the context of a whole pipeline.
Same logic, different engine. Because each function is isolated and declarative, it’s easy to swap implementations without rewriting pipelines. The inputs are well-scoped, the environment is explicitly defined, and outputs follow a consistent structure.
In other word, instead of configuring jobs, we’re writing Python, just with clear boundaries, a vertical data integration, and as consequence fewer surprises.
Git for Data
One of the hardest problems in data workflows is reproducibility. In software, it's a given: you check out a commit, install dependencies, and rerun the same code with the same results. However, with data workflows, things are a bit more complicated: code is versione, environments might be, but data almost never is. And when it is, it's handled informally: duplicating files, appending timestamps, overwriting tables, making undocumented changes, etc.
If a pipeline fails or an output looks wrong, the questions start piling up: what code produced this result? Which version of the data was used? What environment did it run in? Can I reproduce the error exactly?
We addressed this problem by versioning all the key components of a pipeline together: code, environment and data. We use Apache Iceberg as the foundation for table storage, so each table is backed by Parquet files on object storage, with a transactional metadata layer that tracks snapshots and schema evolution.
This makes it possible to:
- Track what changed in each run
- Restore any table to a prior version
- Compare table states over time
- Audit which code and inputs produced an output
This setup allows to support the concept of data branches: logical branches that isolate changes to our data. These are like Git branches, but for tables. We can create a branch, test new logic, and only merge when we are ready. Thanks to Iceberg’s zero-copy metadata model, these branches point to existing snapshots rather than duplicating data, which makes them instantaneous and efficient.
Each run now produces a commit and each commit records the changes to the data lake along with the input and output data, the execution environment, and the code version. In this way, if something breaks, we can use that commit to:
- Re-run the job with the same context
- Restore tables to a previous snapshot
- Debug the exact environment that was used
With this model, reproducibility is fully built in, which turn out to be very useful in order to build robust systems that are easy to debug and make simple to comply with regulatory constraints due to industry regulations.
This should bring us full circle: data workflows become testable, inspectable, and manageable just like any modern software system. We can branch, merge, revert, audit, and rerun using our data lake on object storage as the a single source of truth.
Wrapping Up
For all the progress we’ve made in AI, data engineering still feels like a holdover from an earlier era. You can spin up an LLM with a prompt, but reproducing a data pipeline run from last week still takes an astounding amount of work.
Python has become the default language for AI and data, but the ecosystem around it hasn’t kept pace. We’re still lacking a clear reference architecture to run data in the cloud at scale in a Pythonic way.
The idea is fairly simple: if AI makes data a first-class citizen in software systems, then data platforms should start acting like software platforms too. Bauplan is our attempt to bring those ideas together. Functions over tables. Commits and branches over object storage. Reproducibility by design, not as an afterthought. There’s still a lot to build. But if we get the foundation right, the rest starts to look a lot more like software and a lot less like plumbing.
Thanks to Pete Soderling and Sean Tylor for making it possible and to all the folks who chimed in for the discussion at Data Council.




