Git for Data: Formal Semantics of Branching, Merging, and Rollbacks (Part 1)



See the repo in Github.
Git’s semantics
“Logic will get you from A to B. Imagination will take you to some weird state of your Git repository.”
Albert Einstein (sort of…)
Ten years after its introduction, a computer discovered a sequence leading Git into a “potentially wrong state”. Potentially is the operative word here, because for a while the Git community could not decide whether this was an intended behavior or a bug.
Git’s inner working is notoriously hard to grasp, even for developers who uses it on a daily basis (after all, it was introduced as the information manager from hell by Linus Torvalds himself), but this anecdote shows something more profound. The point of the story is not that the system is complicated, the point is that it was not clear whether a bug was discovered or not.
The problem stems from lack of a precise formal semantics for Git, an exact description of how every command transforms the repository states. Without a formal system, the only way to know what a complex sequence will do is to run it and see, which makes it hard to uncover potential bugs and can create a fair amount of confusion even among advanced users.
To replace the guess-and-check cycle with proof, we need formal semantics. Once behavior is formally specified, we can reason about all possible executions a priori rather than discovering edge cases by accident.
Why we need formal models
When software systems are small and simple, it's easy to reason about them by reading code, writing some tests or comparing different implementations. However, as systems grow in complexity our intuition quickly breaks down and it is impossible to look at the code and realistically predict its behavior in every possible scenario.
This is where formal methods step in. Formal methods provide a mathematical framework for precisely specifying and verifying how a system should behave without having to run it.
- We begin by writing a formal specification, often in the form of logical rules, invariants, or state-transition models that precisely state your system’s correct behavior.
- Then, using tools like model checkers or theorem provers, we automatically explore every possible behavior defined by the formal specification.
- If the system satisfies all specified properties in every case, we’ve proven its correctness.
- if not, the tool produces a counterexample, that is a concrete execution trace that violates the spec. That counterexample highlights a potential flaw, and forces us to decide whether it's a bug worth fixing.
Typically, formal proofs are used where systems are extremely complex and even edge-case failures can have catastrophic consequences. For instance, AWS uses formal methods to define for Lambda’s execution model or verify the consistency of S3’s storage nodes. The DARPA’s HACMS project used formal verification to build drone autopilot software that was mathematically proven free of whole classes of security bugs. Git is the kind of system that becomes very complex very quickly, because it is essentially built to deal with scenarios where many different actions can be taken simultaneously.
What is Git-for-data
At Bauplan, we spent a lot of energy developing what we call Git-for-Data, the simple idea that many problems in modern data work can be tackled by bringing Git-esque abstractions into complex data workflows.
Why do we care so much about this? Because the current lifecycle for building and operating data applications is still surprisingly fragile and inefficient. A huge amount of valuable data sits unused because working with it is slow, risky, or error-prone. A lot of organizations go through this cycle several times (I know because I sat through that more than once myself):
- We want to use our data to improve our decisions and build better applications. But because data is hard to use, we get much less value than we could.
- Hire a bunch of data engineers and data scientists, and purchase a bunch of new tools!
- Things have actually become more complicated and slow now.
- Return to 1.
Git-for-Data changes this by giving data teams the same robust, safe development practices that software engineers have been using for decades to ship software at scale:
- data branching for safe experiments and collaborations,
- data commits for full reproducibility,
- merges for robust production deployment,
- and rollbacks for easy recovery when something goes wrong.
In other words, it makes it radically simpler and safer to work directly on production-scale data and gives a clearer way to manage change without losing your footing.
In real organizations, data is never a solitary endeavor. Data serve multiple teams for many business needs and applications and these teams routinely touch the same core tables at the same time. Take this scenario: your ML team is developing new derived features for a churn prediction model, they add new columns and tweak data types in the customer_events table. Meanwhile, the analytics team restructures the same customer_events table to power a new retention dashboard, rewriting parts of the schema to fit BI needs.
Without guardrails, these changes can collide silently:
- The ML pipeline trains on an outdated or mismatched schema.
- The dashboard reads inconsistent snapshots, showing unreliable KPIs.
- Teams waste hours debugging a conflict they didn’t know they created.
A Git-for-Data system should help solve this problem by enabling each team to work in its own branch, make schema or data changes independently, and test those changes in isolation. When they’re ready, they merge back to main, but the system checks for conflicts before anything hits production. Conflicts don’t become a problem because someone notices that a dashboard is broken: they are caught before, when the change is proposed.
Going beyond the analogy
All of this sounds promising, but returning to our original question: does Git-for-Data come with a formal semantics that guarantees predictable behavior? The answer is a resounding no. To be honest, even if the expression “git-for-data” has been used by different projects, at the current stage it is little more than a loose analogy. Its meaning varies across different projects because there is no shared conceptual model between them.
Projects like Nessie, lakeFS, DVC, and XetHub all use the Git-for-Data intuition in different ways. Nessie brings branching and commits to the catalog layer for Iceberg. lakeFS adds versioning on top of object storage with atomic commits and hooks. DVC tracks dataset and model versioning for ML experiment tracking. XetHub pushes Git semantics to huge binary files with block-level deduplication. Each solves a slice of the problem, but there’s still no shared, formal model behind them.
In this blog post, we will try to dig into the formal foundations of Git-for-Data for Apache Iceberg and Data Lakehouses.
Our question is: how can we push the Git analogy for data workflows? For instance, how many commits should I expect when working on (and merging) a “feature branch” in my lakehouse?
We use Alloy to define our formal specs and run our verification. By modeling the relevant abstractions, formal methods identify corner cases, weird bugs, edge conditions, and safety violations that simple testing may never cover, offering proof-level guarantees about system correctness. On the other hand, it’s important to remember that standard tests are much easier and cheaper to write, so every well-thought project will feature all testing strategies, each with its own trade-off: unit tests, integration tests, simulations and formal proofs.
This is a blog post that you can run and it comes with our open-source computational model, so clone the repo and tag along.
Git-for-Data: workflows and primitives
At Bauplan, Git-for-Data runs in production today and solves two real coordination challenges that every serious data team hits eventually.
1. Fast, safe development — Single Player
Most teams still prototype new pipelines by pulling extracts into notebooks or dev environments. This keeps production safe but causes drift and delay: when it’s time to push to prod, you’re rewriting code, retesting it, and handing it off to platform teams which often adds weeks of friction.
Git-for-Data fixes this by letting developers spin up branches directly over live production data, in parallel with feature branches on Git for code. A typical single-player workflow looks like this:
- Start with source table
Sin themainbranch. - Apo creates a
featurebranch and adds tableTinfeature. - Apo merges
featureback intomain.
Without touching any data, can we tell how many commits this scenario should produce in the lakehouse? Can we carry over the typical Git reasoning for code?

2. Concurrent work — Multiplayer
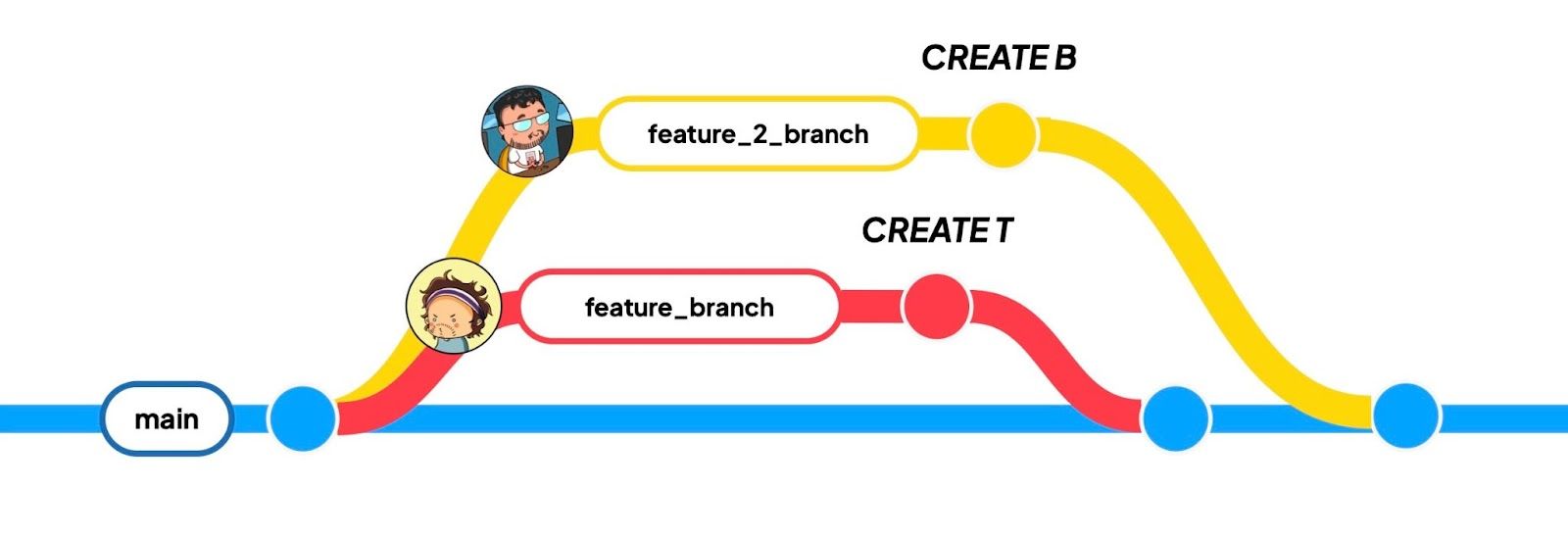
To discuss our formal modeling, we start from the simplest possible workflow, extending our single player case to two developers making modifications to different tables in their own branches. This is the scenario in our a minimal multiplayer workflow:
- Start with source table
Sinmain. - Apo creates a
featurebranch, adds or modifies tableT. - Big creates
feature2, adds or modifies tableB. - Apo merges
featureintomain. - Big tries to merge
feature2intomain.
Again, the question remains whether we can tell how many commits this scenario should produce in the lakehouse. Is this different than the previous scenario? Can we carry over the typical reasoning from Git? How would your answer change if Big was also creating T?
The conceptual primitives
To answer our questions in a principled way, we start by isolating a small set of primitives to model the two scenarios above. Interestingly, even this small subset of lakehouse notions is enough to describe interesting behavior.
How we test it: Alloy
We don’t want to think of Git-for-Data as just a convenient analogy: we want its guarantees to hold up under pressure. We use Alloy, a lightweight model checker, to stress-test the core logic behind our branching, commits, and merges.
To start simple and make sure our models are expressive enough to get the basic facts right, we write a formal specification of our primitives. We then use Alloy to run the scenarios and verify our Git-inspired constraints: since the answer to our questions lies in reasoning about no-conflict merges, it is naturally to computationally explore what happens at merge time.
Let’s start by running the single player scenario:
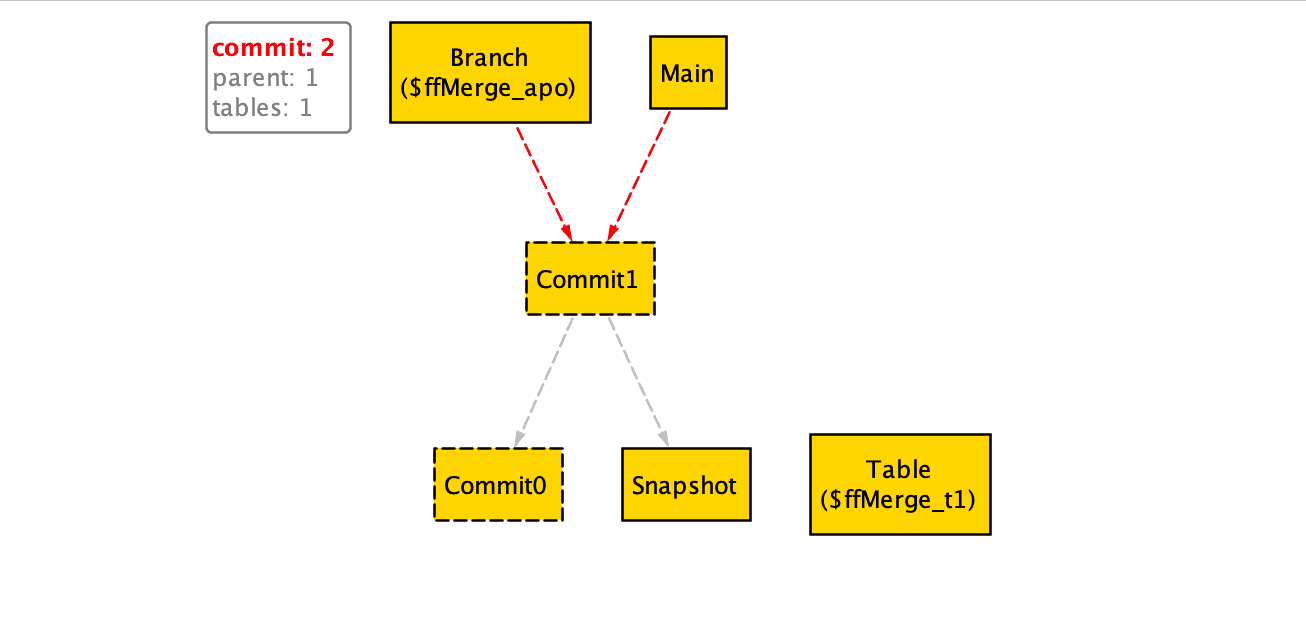
Alloy finds that, if no other changes happen, it is consistent with our primitives to merge feature by simply moving main forward. Now, let’s turn to the multiplayer scenario:
Alloy shows that the system must create a new commit that reconciles both changes.
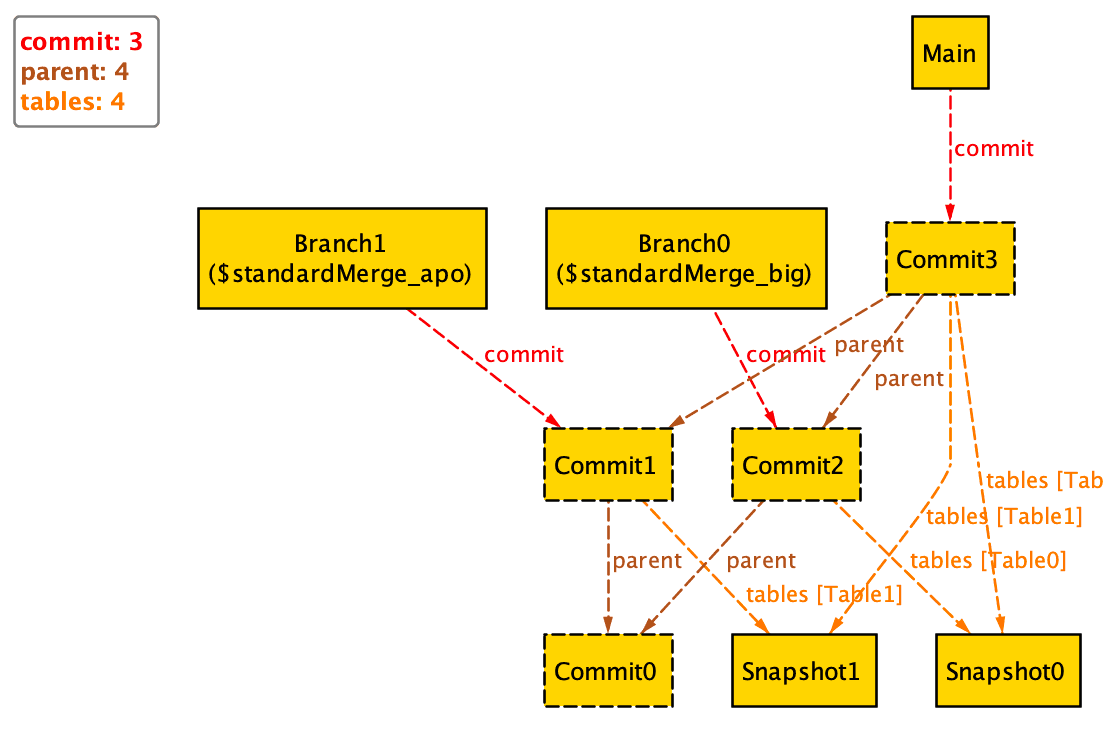
Alloy shows through interpretable traces that the two scenarios provide indeed two different answers to the question “how many commits should we expect?”.
This not only clarifies how all the moving pieces interact, but it can help writing better integration tests, in a virtuous circle from formal reasoning to application code.
Once again, this model doesn’t simulate runtime failures or network partitions: it’s rather focused on logical correctness of Git-style state transitions. That’s the layer where guarantees matter most for merge safety and reproducibility.
From models to systems
Different systems inspired by Git will make different choices, perhaps for technical reasons, perhaps to better suit their use cases.
That goes also for Bauplan. For instance, Bauplan always creates a merge commit, even when a fast-forward would be possible. That’s a deliberate design decision, that is very hard to spot from outside. The good news is you can inspect these behaviors directly because the system exposes clean, typed APIs, so you can script out branching and merging scenarios and explore the resulting commit graph. Here is an example that you can inspect and run.
The deeper reason we built these models isn’t to catch strange edge cases, but to clarify the semantics that Git-for-Data systems should have. Because Git-for-Data is still a new concept, no one has nailed down what it really means, and because data is sensitive and mistakes tend to be expensive, we don’t want to leave these gaps open.
Our interest in going deeper into the formal semantics of our Git-for-data really lies in making sure that every time you branch a pipeline, test an experiment, or merge a teammate’s work, you’re relying on guarantees that are more than a loose analogy. While no proof can guarantee EC2s won’t die, they can indeed give you the confidence of consistent tables even if the EC2 dies.
Isolation, conflict safety, and rollback are the fundamentals you already trust when building software. We want to bring the same guarantees to your data lakehouse so that it’s truly developer-friendly, even at scale. When teams can branch, merge, and rollback without fear, they can move 10x faster and 100x more confidently.
So the real question is: how should we reason about these differences? What does it mean to compare a spec to a live system? And how do we tell which behaviors are essential, and which are just policy?
We’ll dive deeper into those questions and into Bauplan’s Git-for-Data semantics in the next post.
Acknowledgements
Our interest in "git-for-data" started at the very beginning of Bauplan. Our formal work is being carried out with the help of Manuel Barros (CMU), Jinlang Wang (University of Wisconsin, Madison), Weiming Sheng (Columbia University). In particular, Manuel devised the Alloy model used here.




