Everything-as-Python


“Good design is actually a lot harder to notice than poor design, in part because good designs fit our needs so well that the design is invisible”. Donald A. Norman, The Design of Everyday Things.
Data and ML scientists - A life in the middle
Despite AI eating the world and data becoming one of the most important things for every company on the planet, but getting models from prototype to production is still pretty problematic. According to HBR, fewer than 1 in 5 models ever make it into production. And when they do, it often takes weeks or months.
Good data scientists have a special skill set in data manipulation, math, statistics and machine learning. Great data scientists are also very aware of the business problem and the business need. In my experience, the closer data scientists are to the problem, the more impact they create.
Now, in many cases, that closeness has to extend all the way into production which means that data scientists must be involved with software development. Most real-world ML projects today, like recommendation engines or RAG systems, require a working understanding of software engineering and its best practices (incidentally, these use cases are often the most valuable because they impact final users directly).
Now, what is the problem with that? Well, these kinds of applications require real software and infrastructure expertise, and while most data scientists know enough Python to explore data and build models, they’re usually less comfortable with the rest: distributed systems, cloud environments, CI/CD, testing frameworks, data lakes, and the messy reality of production-grade software.
The perilous road from notebooks to production
When asked, countless companies end up telling us the same story: data scientists produced a working prototype on a Jupyter notebook, but it is unclear what happens next.
Historically, the industry has defaulted to one of two options — neither of them ideal.
Option 1 - Ship the notebook and YOLO. Some of the most well-established early platforms for data science, like Databricks or Domino Labs, solved this problem by essentially allowing data scientists to ship their Jupyter notebooks directly to prod.
This makes things kind of quick but very fragile. Jupyter notebooks are notoriously brittle things, that break execution order, hide state, and make reproducibility a gamble.
Option 2 - Hand it off to DevOps. The other option is to have data science produce prototypes that can be on Notebooks and then have a devops team whose job is to refactor those into an application that runs in production. This process makes things less fragile, but it is slow and very expensive.
As a manager, I’ll add this: I don’t really like either of them because they both silos data people even more, instead of fostering processes where software engineering best practices are followed across organizations and create inefficient team topologies with diluted ownership.
Everything as Python: this is the way
Today, we want to show you a different path, one that avoids both the fragility of productionized notebooks and the complexity of cross-team handoffs.
We’ll walk through a complete prototype-to-production workflow using two Python-first tools:
- marimo — a modern open-source notebook, stored as Python files, that keeps the flexibility of Jupyter but adds reproducibility, maintainability, and reusability.
- bauplan — a cloud data platform designed for Pythonic workflows over S3, with built-in data versioning, declarative environments, and function execution.
The core intuition here is that both tools are code-first, which means they speak the same language: Python.
That gives us composability “for free”: your prototype code does not need to be rewritten to go into production. We’ll show you how that works.
Prefer to run the code yourself?
Check out the repo, get a free API key from the Bauplan sandbox, and follow along.
Iterating in a Notebook with marimo
In this example, we will clean and analyze a sample of the NYC taxi dataset. The data we’re working with isn’t sitting on our laptop. It lives in an S3 bucket — just like it would in a real production environment.
Now enter marimo, a new kind of notebook. It looks like Jupyter, but behaves like a script. That means:
- Execution order is enforced
- Variables are scoped properly
- Code is cleanly structured and reusable
To run your marimo notebook just type:
We’ll get the data from two separate tables:
taxi_trips_sample: trips over a fixed time windowzones: metadata about NYC neighborhoods across all five boroughs.
We will see what these table are in a minute, for now let’s not be too formal and adopt the following definition:
“A table is a thing with columns and rows, and you can apply filters to it.”
Let’s start with defining our dependencies at the top:

Then we use Bauplan’s Python SDK to connect to our data catalog and load the tables as Polars DataFrames:
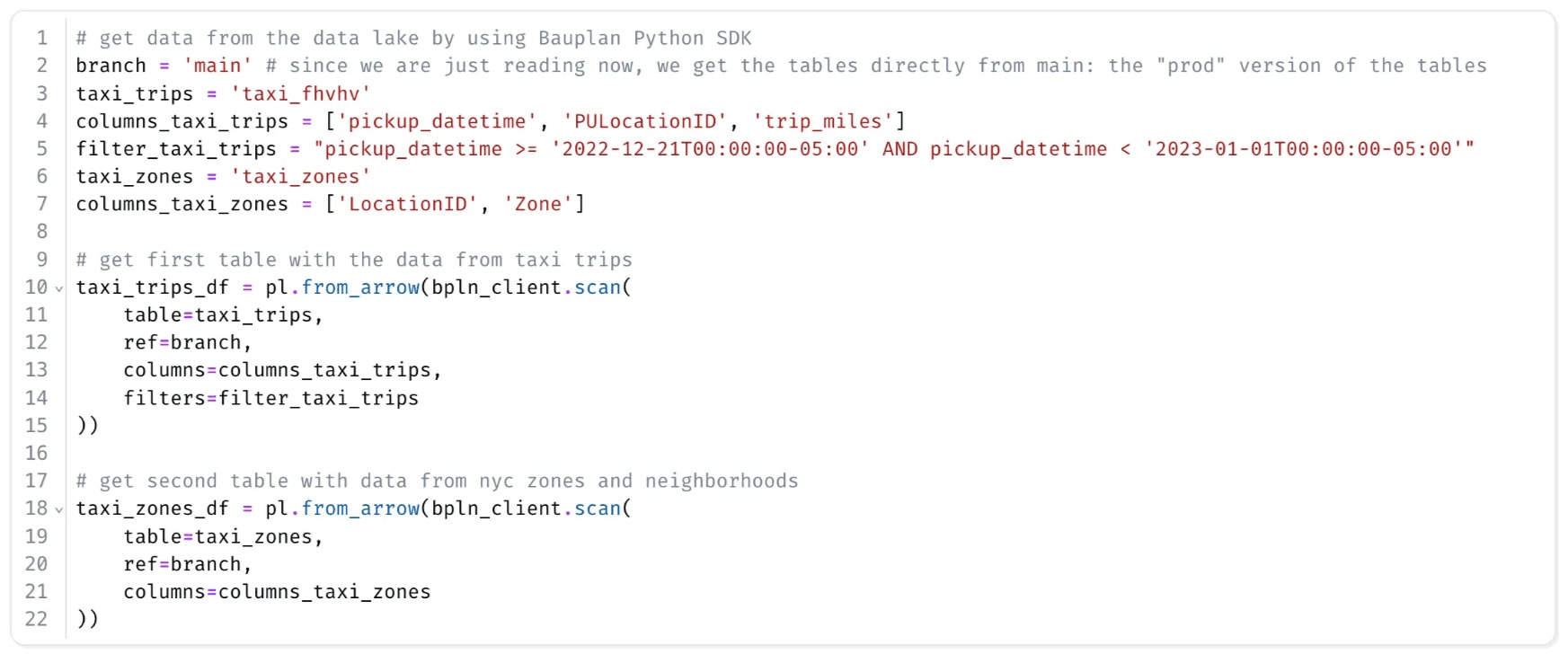
Let’s unpack what’s happening under the hood. When we call bauplan.client.scan(), Bauplan:
- Fetches the data from S3
- Avoids redundant reads via smart caching
- Streams large datasets efficiently
- Handles the data versioning in a data branch (see below)
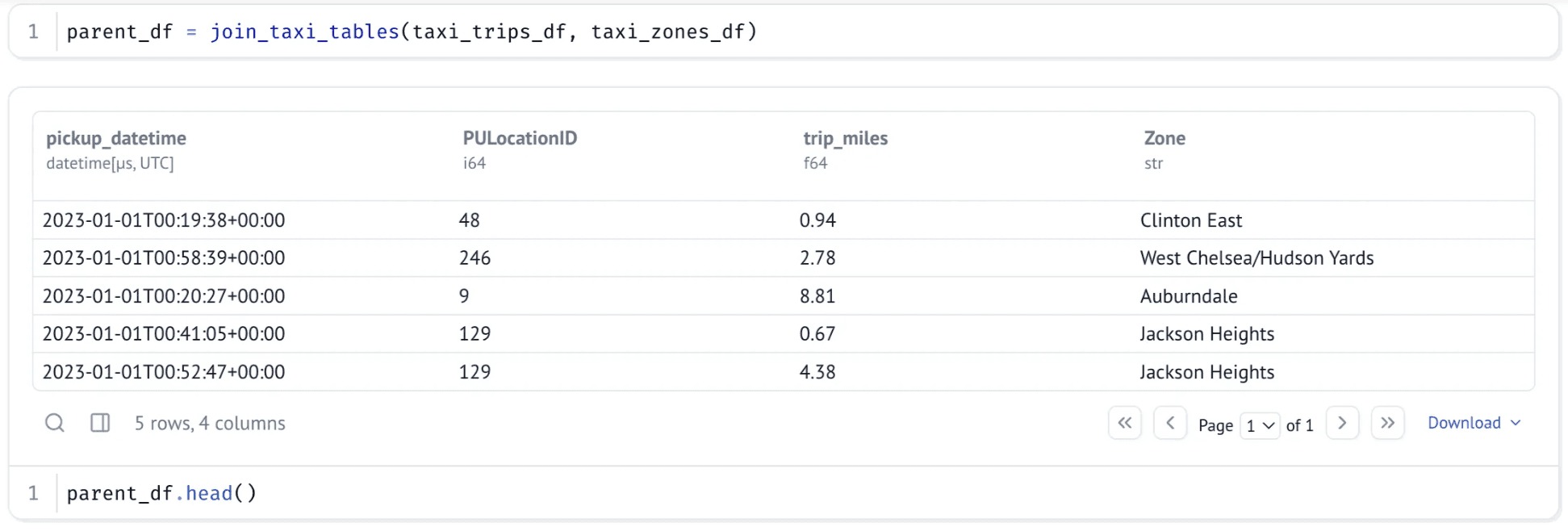
We define our first transformation: a join between the two datasets. Wrapped as a Python function, it returns a new DataFrame — which we inspect visually using marimo’s built-in tools:

Next, we define a second transformation that cleans up the data and computes some aggregates, again, as a plain Python function.
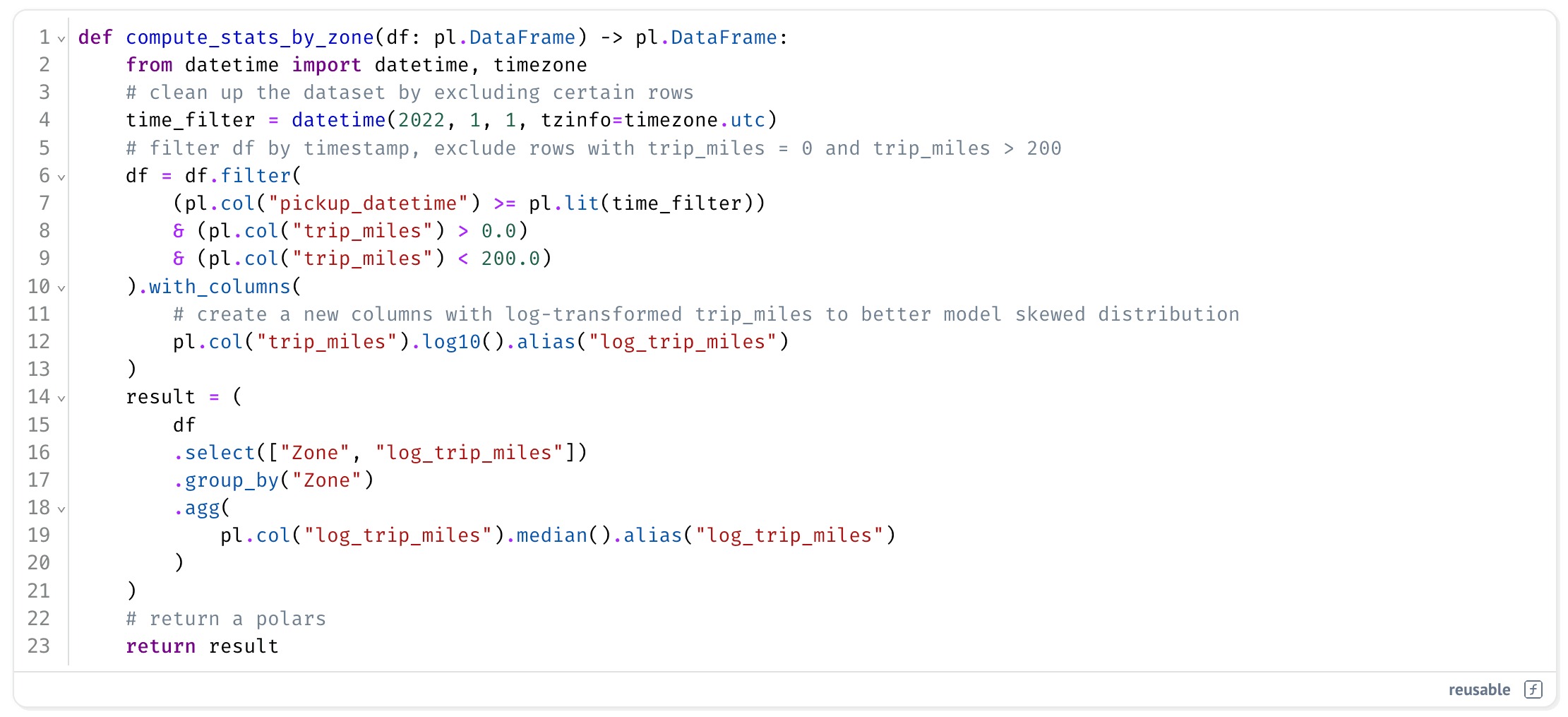
Still looks like a notebook, right? But here’s the key difference. marimo notebooks are just Python scripts, so every function you define can be reused outside the notebook, including inside a Bauplan pipeline.
Building a production pipeline with Bauplan
While it is easy to blame data folks for not being good at software, the truth is, as we noted elsewhere, that the sheer quantity of tools needed to run data workloads in Python in production is astounding. Python data pipelines in the cloud are Rube Goldberg machines of storage, file formats, table formats, containers, environments, orchestration and so on.
Below, the things you need to run a data pipeline in your production cloud environment.
Bauplan is designed to solve this problem and provide a much simpler developer experience. It’s a Python-first, dead-simple data lakehouse that abstracts away production infrastructure, while keeping everything in code.
Here’s how it works:
- Data are just tables — with columns, filters, schemas, and versioning, built-in on your S3. We can use those tables in our Python code declaratively.
- DAGs are just functions chained together — parents feed children, like in the notebook logic illustrated above.
- Infra is just decorators — all dependencies are declared in the code, so there are no Dockerfiles or Terraform scripts.
- Runtime is optimized, serverless Python — fast cold starts, built-in scaling, no setup required.
- Data is versioned like Git — versioning is built-in so every table, model, and result lives in a Git-like branch of our data lake.
The last point might need a little more explanation. In Bauplan, we don’t just version your code, we version your data too. Every operation on the data lake lives inside a branch, just like Git. As a consequence, we can prototype, test new logic, or tweak filters on production data without affecting downstream production systems.
When we imported data into polars dataframes in the section above, you may recall that bauplan.client.scan() requires a branch as input. That is because you’re not just performing a scan on a table in S3: you’re scanning a specific version of that table.
This model turns out to be extremely useful in the process we are describing because it enables:
- Safe experimentation
- Collaborative workflows
- Reproducibility by default
From Notebook to Pipeline, quite literally
Here’s where it gets good: because both Bauplan and marimo are truly Pythonic, we can take those exact same functions we wrote while prototyping in our notebook and run them in production without any refactoring.
All we need to do is wrap the two functions in Bauplan decorators, whose semantics is pretty obvious even for beginners. We start by importing the function we wrote in our notebook join_taxi_tables and wrap it in a Bauplan model. We define the input tables, columns, filters, and dependencies using simple Python.
Then, we define a second function stats_by_taxi_zones to compute our stats. This second function takes the output of the first function as input and writes the result back to the data lake, thanks to the materialization_strategy parameter being set to REPLACE:
Both functions live in a Python file and they run as fully containerized functions in the cloud. Running the pipeline in the cloud becomes as easy as launching a local script: just use the bauplan run command:
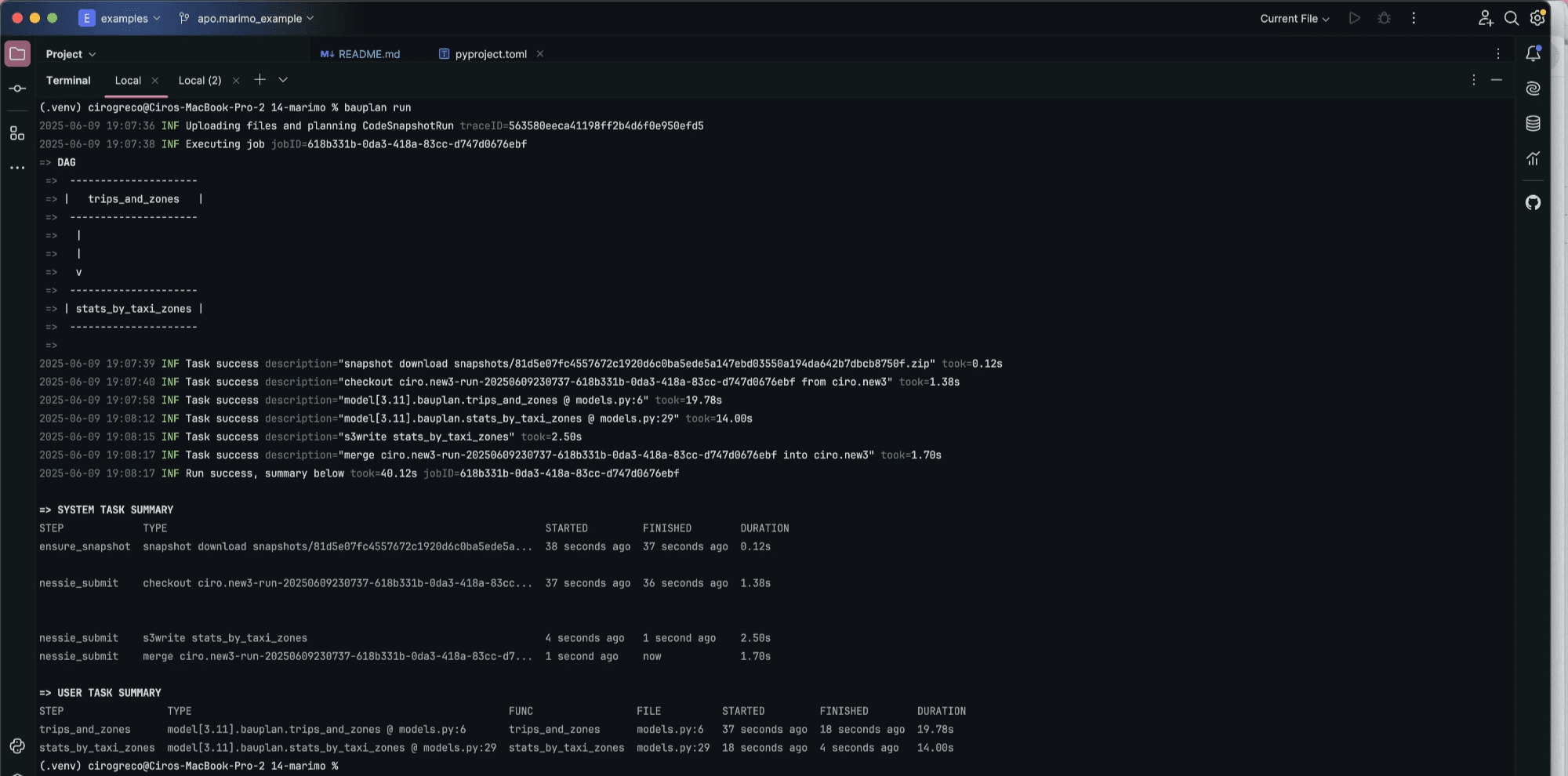
A couple of notes on what happens:
- The parent function (
trips_and_zones) uses the same data as the notebook, but now applies a full-year filter, because we’re in the cloud and we are not limited by local memory. - The marimo functions are reused as is: they’re just Python functions, imported like any other module.
- You’re free to use Pandas, Polars, or anything else. Bauplan doesn’t care as long as one can pip install it (in real deployments, this include your own private packages as well!).
- Best of all, the output of the DAG is saved to your branch. You can share it with other developers or with our PM for feedback, validate the logic, and when ready, merge it back to main.
The main point is that we don’t have to worry about any infrastructure and we don’t have to refactor our notebook into jobs.
So, what happens if we update the function stats_by_taxi_zones in the notebook and change median to mean and re-run it? Nothing new to learn, really. We just save the notebook and go again:
Our production-grade data pipeline just updated itself.
What’s next?
Bauplan + marimo show that going from prototype to production doesn’t have to be painful. No handoffs. No rewrites. No YAML jungles or container rabbit holes. Just Python — in notebooks, in pipelines, in production.
That said, there are still a few rough edges we’re working on.
One common question: how do I map the setup cell in marimo to Bauplan’s decorators? Today, you copy the package list into a @bauplan.python(...) decorator. It works, but we agree — it’s not ideal.
We’re actively building support for shared, declarative environments scoped to folders or DAGs, so that your dependency setup can be reused across tools — notebook or not — without duplication.
Try It Yourself
Checkout our integrations page for marimo notebook!
Try Bauplan, it's free!
Try Marimo, it's open source!




